クラスとオブジェクト指向
本講で学ぶこと
- オブジェクト指向
- クラスとインスタンス
オブジェクト指向とは
オブジェクト指向プログラミング (object-oriented programming)という開発方法がある。オブジェクト指向によりプログラムを組むという方法論だ。では、オブジェクト指向とは何か。実は筆者にもよくわからない。この言葉の意味するところはプログラミング言語によって異なるし、人によっても違うイメージを持っているであろう。とりあえずここでは「オブジェクト指向とは、プログラミング技法の一種である」と思っておけば良い。
オブジェクト指向には様々なキーワードが出てくる。例えば以下のようなものだ。
- オブジェクト
- クラス
- コンストラクタ
- インスタンス
- メッセージ
- カプセル化
- ポリモーフィズム
- 継承と合成
これらについて「たとえ話」を使って説明することはできる。それを聞いて「ぼんやりとわかった気」にもなるだろう。しかし、個人的な経験で言えば、オブジェクト指向の用語を「たとえ話」で「わかった気」になってもほとんど意味がない。あくまでもオブジェクト指向はプログラミング技法の一種であり、プログラムを組みながらその感覚を身につけるものだ。そこで、本稿では詳細には触れず、とりあえずクラスを使ったプログラムを組むことで記述の仕方に慣れることを目標にしよう。本稿を読み終わった後に
ひな形であるクラスから作ったオブジェクトをインスタンスと呼ぶ。オブジェクトは内部状態を持ち、メソッドというインタフェースを公開している。プログラマはメソッドを呼ぶことでオブジェクトにメッセージを送ることができる
という文章がだいたい理解できていればそれでよい。
オブジェクトとは
オブジェクト指向には、オブジェクト(object)という概念が出てくる。これは「データ(内部状態)」と「振る舞い」をまとめたものだ。オブジェクト指向プログラミングでは、オブジェクトに何か処理を「依頼」することでなんらかの処理をする。この「依頼」をメッセージ (message)と呼ぶ。Pythonでは、次のような形でオブジェクトにメッセージを送る。
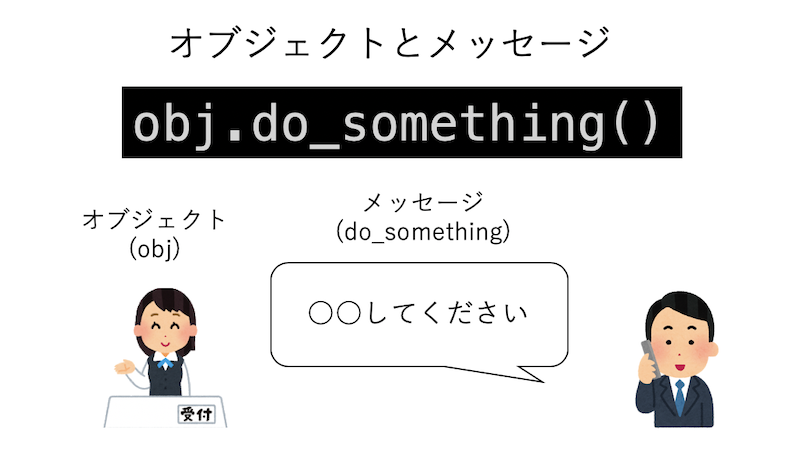
obj.do_something()ここで、ピリオドの左にあるobjがオブジェクトであり、メッセージを受け取るのでレシーバ(receiver)と呼ばれる。逆に、メッセージを送る側はセンダー(sender)と言う。ピリオドの右にあるdo_something()はメソッド(method)と呼ばれる。Pythonでは、オブジェクトの持つメソッドを呼び出すことでメッセージを送る。オブジェクトは、自分の「状態」を持ち、メソッドという外部インタフェースを持つ。
カプセル化
なぜオブジェクト指向プログラミングをするかというと、それはオブジェクトに責任を移譲するためだ。例をあげよう。社員データをまとめたデータベースがある。社員データは以下のデータを持つ。
- 名前(文字列)
- 年齢(整数)
- 所属部署(文字列)
各データには以下の制約がある。
- 名前は20文字以内
- 年齢の数値は正
- 所属部署は「A課」「B課」「C課」のいずれか
さらに、データはウェブから入力されたり、ファイルから追加されたりと、複数の新規作成パスがあるとする。
この状態で、まずウェブルーチンで何かしらチェックをする。
if len(name) > 20:
# エラー処理
if age < 0:
# エラー処理
if group not in ["A課", "B課", "C課"]:
# エラー処理
#データ追加処理
data.add(name, age, group)同様に、ファイルからの入力でもチェックをしなければならない。
if len(name) > 20:
# エラー処理
if age < 0:
# エラー処理
if group not in ["A課", "B課", "C課"]:
# エラー処理
#データ追加処理
data.add(name, age, group)さて、この状態で、将来「D課」が増えた時、両方のルーチンを修正しなければならない。このように似たような処理を複数回記述していたら危険信号である。今はデータはウェブとファイルのみから入力されると思っているが、実はいつのまにか別のパスが増えているかもしれない。そこに気が付かないと修正漏れが生じて、それはそのままバグの原因となる。
ここで問題だったのは「どこでデータがいじられているかわからない」ということだ。そこで、考え方を変えて「社員データが正しいかどうかは、社員データ自身が知っているべき」と考えよう。そこで、社員データ「オブジェクト」というものを作る。そして、社員データが正当なものであるかの判断は社員データに問い合わせ、問題なければデータを追加する形にしよう。
person = EmployeeData(name, age, group)
if person.is_valid():
data.add(person)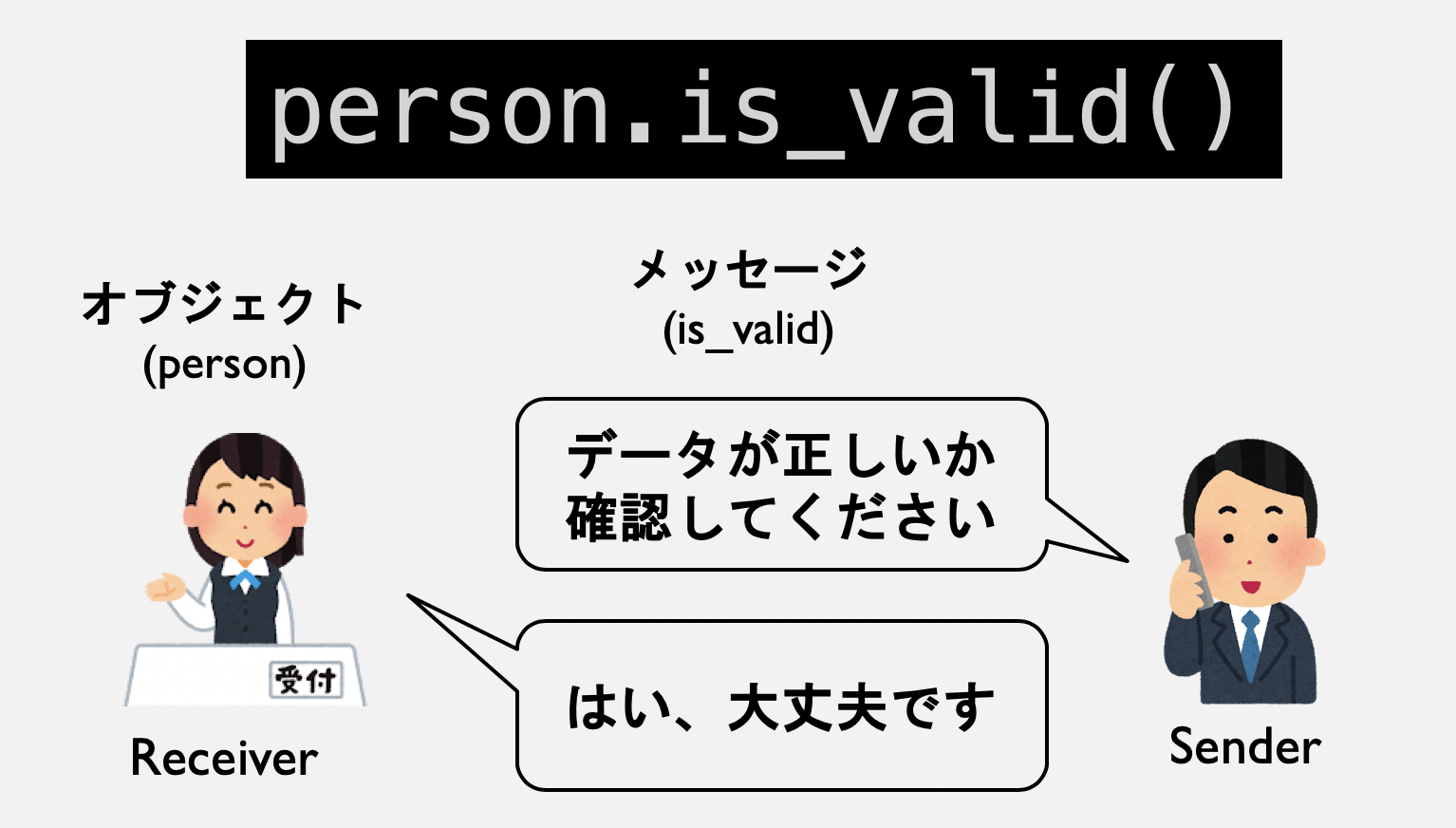
データの正しさは、person.is_valid()という関数(メソッド)の中で行うことにする。もちろんその中身は自分で記述しなければならないが、プログラムを見ると、「データが正しいことを確認する責任が、呼び出し側から、オブジェクト側に移譲されている」ことがわかるであろう。これにより、データが正しいかどうかのチェックは必ずperson.is_valid()で行われることが保証されるため、将来、データの整合性の条件が変更されても、修正箇所はperson.is_valid()一箇所だけでよく、呼び出し側の修正は不要となる。
このように、「データ」を外から見えないようにして、そのデータの修正や追加のためのインタフェースを作って外に公開することをカプセル化(encapsulation)と呼ぶ。カプセル化は、オブジェクトの内部状態を外から隠蔽し、修正する「窓口」を一元化することで、知らない間にデータが修正されている、という事態を防ぐ方法論だ。
今回、カプセル化したのは「各所に散らかっていた似たようなコードを一つにまとめるため」であった。「同じ情報は一箇所にまとめる」という原則を Don’t Repeat Yourselfの頭文字をとって「DRY原則」と呼ぶ。DRY原則はプログラムだけでなく、一般的な作業フローにおいても有用な概念なので覚えておくと良い。
HowとWhat
オブジェクト指向プログラミングの例をもう一つ挙げよう。ウェブで、入力ミスのある項目のラベルを赤字にしていたとする。例えばこんなコードになるだろう。
label.color = redその後、もっと目立たせるために、さらに太字にすることにした。
label.color = red
label.face = boldさて、赤太字にしてみたら、あまりに色が強いので、もう少し違う色にすることにした。この時、ラベルの色を変更している場所全てを変更しなければならない。これはDRY原則に反する。
我々がやりたいこと(What)は、「ラベルを目立たせたい」ということであって、ラベルの色を変えたり太字にしたりするのは、その実現手段(How)であったのだが、もとのコードではWhatとHowが一体化していたのが問題であった。そこで、やりたいこと(What)と、その実現手段(How)がより明確に分かれるようにしよう。
具体的には、ラベルにalert()というメソッドを作り、ラベルを目立たせたい時にはlabel.alert()を呼ぶ、と約束する。
label.alert()そして、目立たせるための実装は、ラベルクラスのalertメソッド内に記述する。
class Label:
def alert(self):
self.color = red
self.face = boldオブジェクト指向であろうかなんであろうが、同じことを実現しているのだから、結局は同じプログラムを書かなければならない。しかし、このような形にすることで、呼び出し側はラベルに「目立ってね」と依頼し、その目立ち方はラベルに任せる、という気持ちでプログラムが組める。こうして置くと、後で「目立たせ方」を変えたい、と思ったときに修正箇所は一箇所で済むため、仕様変更に強いコードになる。
すなわち、オブジェクト指向プログラミングとは
- オブジェクトに責任を移譲し
- How(実装)ではなくWhat(やりたいこと)に集中することで
- 仕様変更に強いプログラムを組む
ための方法論である。
クラスとインスタンス
オブジェクト指向プログラミングにおいては、オブジェクトが中心的な役割を果たすが、そのオブジェクトの作り方には大きく分けてクラスベース(class-based) と プロトタイプベース(prototype-based) の二種類が存在する。
クラスベースとは、クラス(class) という雛形を作っておき、その雛形からオブジェクトを作る方法である。クラスから作られたオブジェクトを、そのクラスの インスタンス(instance) と呼ぶ。C++やJava、Python、Rubyなどがクラスベースのオブジェクト指向言語である。インスタンスを作ることをインスタンス化(instantiation)と呼ぶこともある。
一方、「プロトタイプ」と呼ばれる別のオブジェクトを複製することで新しいオブジェクトを作る。このタイプではJavaScriptが有名だ。
クラス定義
Pythonはクラスベースの言語であるため、まずクラスを定義し、そのクラスをインスタンス化することでオブジェクトを作る。
クラスはclass クラス名:という形で宣言する。
例えば、呼び出されるたびに、呼び出した回数を返すようなカウンターオブジェクトを作ってみよう。
class Counter:
def __init__(self):
self.__num = 0
def count(self):
self.__num += 1
print(self.__num)classというキーワードがクラスを作る宣言である。__init__というのはクラスの初期化のためのメソッドで、コンストラクタ(constructor)と呼ばれる(正確には__init__はコンストラクタから呼ばれる初期化関数であるが、ここではコンストラクタと同一視しておいて良い)。第一引数にselfを指定するのが慣例となっている。ここでself.__numという変数を宣言し、0に初期化している。self.をつけることで、このクラスの状態を保持する変数になる。このクラスに何かさせるためには、メッセージを送るためのメソッドが必要だ。ここではcountというメソッドを作った。やはり引数としてselfを指定し、self.__numで呼ばれた回数をインクリメント(値を1足すこと)してから、その数字を表示している。
このクラスからオブジェクトを作ってみよう。
c = Counter()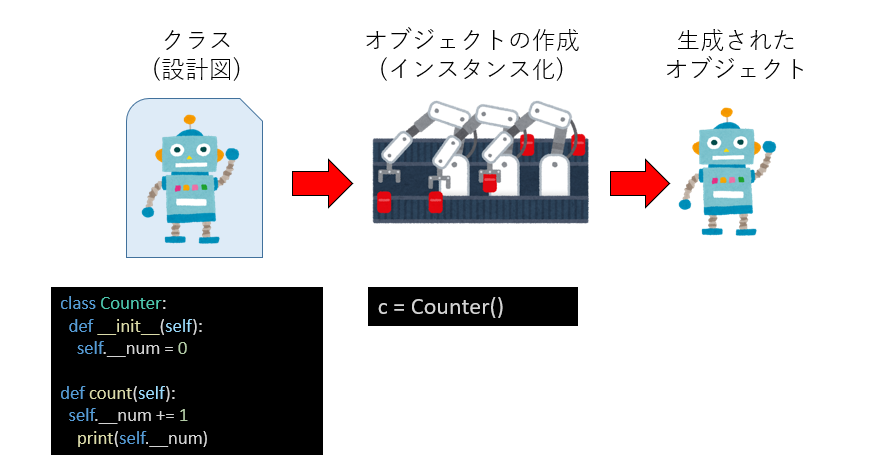
クラス名を関数のように呼び出すと、このクラスのオブジェクトが作られ、それが返される。この時、内部的に__init__が呼ばれている。こうして作られたオブジェクトを、元になったクラスのインスタンスと呼ぶ。
コンストラクタから返されたcがカウンターオブジェクトだ。このオブジェクトのメソッドを呼ぶことでメッセージを送ることができる。
c.count() # => 1
c.count() # => 2
c.count() # => 3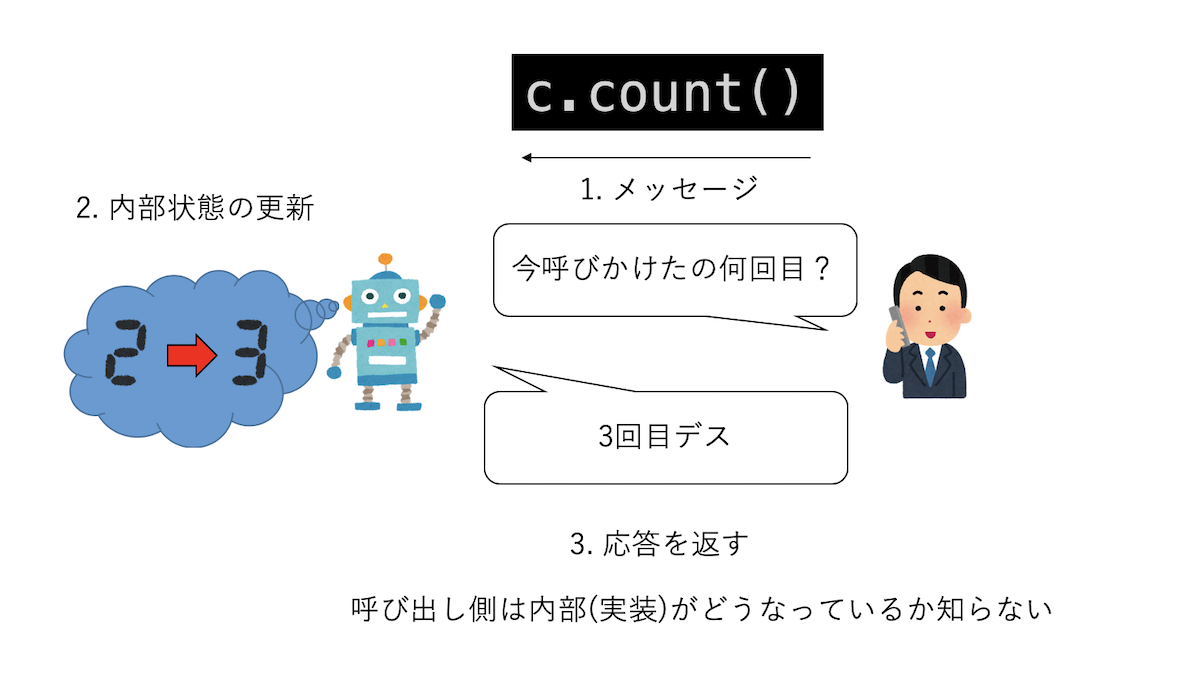
c.count()呼ぶ度に表示される数字が増えていくのがわかる。クラスから別のオブジェクトを作ることもできる。
c2 = Counter()
c2.count() # => 1
c2.count() # => 2新たに作られたカウンターオブジェクトc2は、自分自身の内部状態を持つ。
さて、こうして作ったカウンターの初期値はつねに0だが、任意の初期値を与えたくなったとしよう。この時、__init__に引数を渡すことで、初期値を与えるようにできる。
class Counter:
def __init__(self, ini = 0):
self.__num = ini
def count(self):
self.__num += 1
print(self.__num)# 何も指定しなかった場合、初期値が0になる
c = Counter()
c.count() # => 1
# 初期値を指定することもできる
c2 = Counter(10)
c2.count() # => 11オブジェクト.メソッド名(引数)という形で呼ぶと、暗黙に第一引数としてオブジェクト自身が渡され、それを慣習としてselfという名前で受け取る。
さて、ここで、カウンタークラスはカウント値を属性として持ち、それを修正するメソッドcount()を公開しており、カプセル化の例となっている。ここで、属性__numは外からアクセスできない。
print(c.__num)
# => AttributeError: 'Counter' object has no attribute '__num'これは、変数の名前の頭にアンダースコア二つ「__」がついているためだ。アンダースコアがついていない属性は普通にアクセスができる。
class Hoge:
def __init__(self):
self.value = 123
h = Hoge()
print(h.value) # => 123実は、Pythonではアンダースコアが二つつけられた属性は、名前が_クラス名__属性名に変更される。これをマングリング(mangling)
と呼ぶ。マングリングされた名前を直接指定すれば隠し属性にアクセスできるが、バグのもとなのでやらない方が良い。メソッドでも同様なことができる。
オブジェクト指向プログラミングの実例
オブジェクト指向プログラミングの意義を短時間で伝えるのは難しい。しかし、より学びたい人のために簡単な実例を挙げておこう。
いま、株式会社「Hoge」があり、その社員の名簿がある。社員は社員IDとメールアドレス(例えばsato@hoge.co.jp)を持っている。プログラマである田中君は、それをリストで実装した。
name = ["佐藤","鈴木","高橋","田中"]
address = ["sato", "suzuki", "takahashi","tanaka"]メールアドレスの@の右側は全員同じなので、@の左側の部分だけ保存されている。例えば鈴木さんは社員番号1番であり、メールアドレスは
sato_address = address[1] + '@hoge.co.jp'で取得できる。さて、この会社が戦略的な理由により、子会社「Fuga」を作成し、高橋さんが社長としてその会社に移ることになった。田中くんは「メールアドレスの@の右側は全社員同じ」という前提でプログラムを作ってしまっていたので、全プログラムの社員アドレスを取得している箇所を修正しなければならない。
また、子会社ができたことにより、社員番号の扱いも変えなければならない。高橋さんは子会社Fugaの社員番号0番であるべきだ。どうしよう?別に所属会社と社員番号のリストを作るべきだろうか?今後両方に所属する人が出てきたら?今後何か変更があるたびにプログラムを全部書き直しなければならないだろうか?
上記のプログラムは、「名前やアドレスを管理したい」という「目的」と、「それをどう実現するか」という「実装」がべったりくっついているところに問題があった。オブジェクト指向プログラミングでは、「目的(振る舞い)」と「実装」を分離する。
実装はともかく、社員データベースdatabaseがあり、そこに社員名を問い合わせればアドレスを教えてくれるようになっているとしよう。イメージはこんな感じである。
takahashi_address = database.address("高橋") # => takahashi@fuga.co.jp
tanaka_address = database.address("田中") # => tanaka@hoge.co.jpこうしておくと、将来子会社が増えた時、databaseの内部実装は変更する必要があるが、databaseに問い合わせている上記の部分のプログラムを修正しなくて良い。
このプログラムは全社員に通し番号で社員番号を付与しているかもしれないし、会社ごとに異なるデータベースを持っているかもしれない。しかし、そんなことはプログラマは気にしなくて良い。
さて、今度は佐藤さんの役職も知りたいとしよう。こう書きたくなるだろうか?
sato_position = database.position("佐藤") # => 課長オブジェクト指向に慣れた人なら、上記のプログラムに違和感を感じるだろう。「データベースに聞けばなんでも教えてくれる」ということは、「データベースが全ての情報を把握している」ということである。会社で「とにかくなんでもこの人に聞け」という人がいたら、その人の責任が過大であり、危険信号であることは想像できるであろう。
そこで、データベースは名前から「社員情報」というオブジェクトを返すことにして、細かい情報はそのオブジェクトに教えてもらおう。総合受付から担当秘書を教えてもらい、詳細は担当秘書に教えてもらうイメージだ。
sato_info = database.info("佐藤")
sato_position = sato_info.position() # => 課長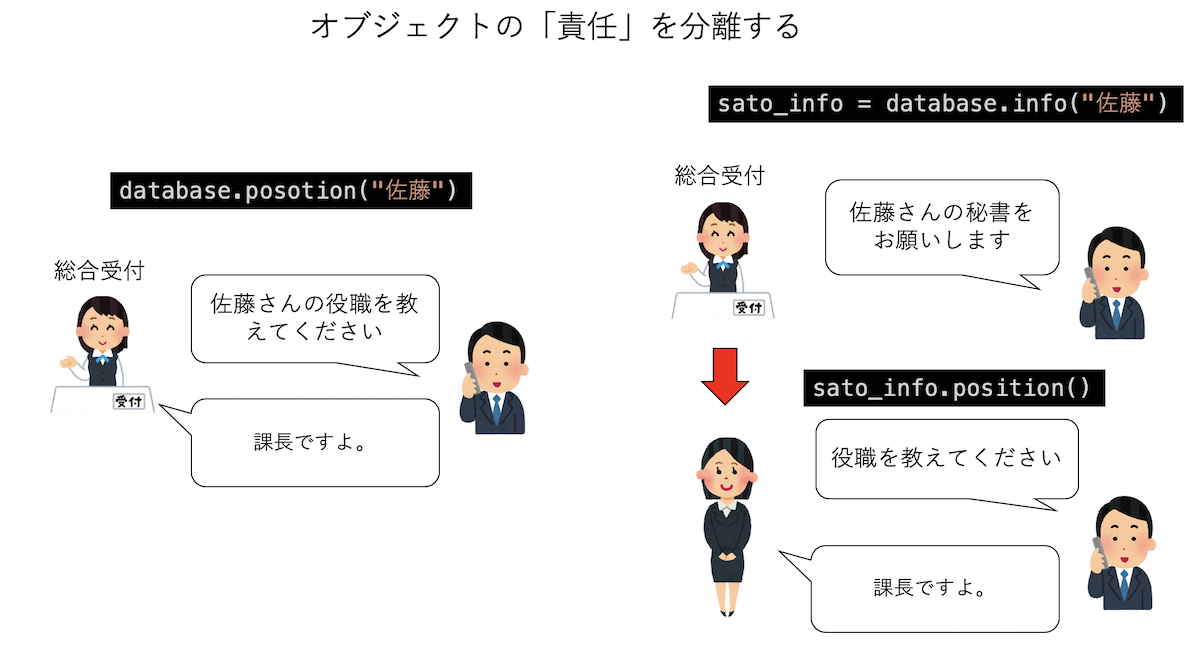
一度、社員情報というオブジェクトを挟むことで、
- データベースオブジェクト(総合受付)は、名前から社員情報を返すのが仕事
- 社員情報は、担当する社員についての情報を担当(他の社員については知らない)
と、「誰がどこまで責任をもっているか」が明確になり、かつ「オブジェクト同士の責任が重なる」こともない。
ちなみにsato_infoを消して、メソッド呼び出しをピリオドでつなげることもできる。
sato_info = database.info("佐藤").position() # => 課長オブジェクト指向に慣れたプログラマは「こういうオブジェクトはこういう振る舞いをして欲しい」とか「このオブジェクト(クラス)の責任が多すぎるな」といった「お気持ち」を持つ。この「お気持ち」に沿ってプログラムを組むと、バグが少なかったり、将来の仕様変更に強いプログラムができる。オブジェクト指向はそういう「プログラミングノウハウ」を形として具現化したものだ。ある程度大きなプログラムを組んでみないと、このあたりの感覚を身につけることは難しい。
本稿も含めて、巷にあるオブジェクト指向の説明においては「たとえ話」が頻出する。たとえ話はなんとなくイメージを掴むのには有用であるが、オブジェクト指向がプログラミング技法である以上、いくらわかった気になっても実際に使えなければ意味がない。あくまでもプログラムの具体例に数多く触れ、経験を積み重ねていくのがオブジェクト指向の理解の早道であろう。
割りばしゲーム
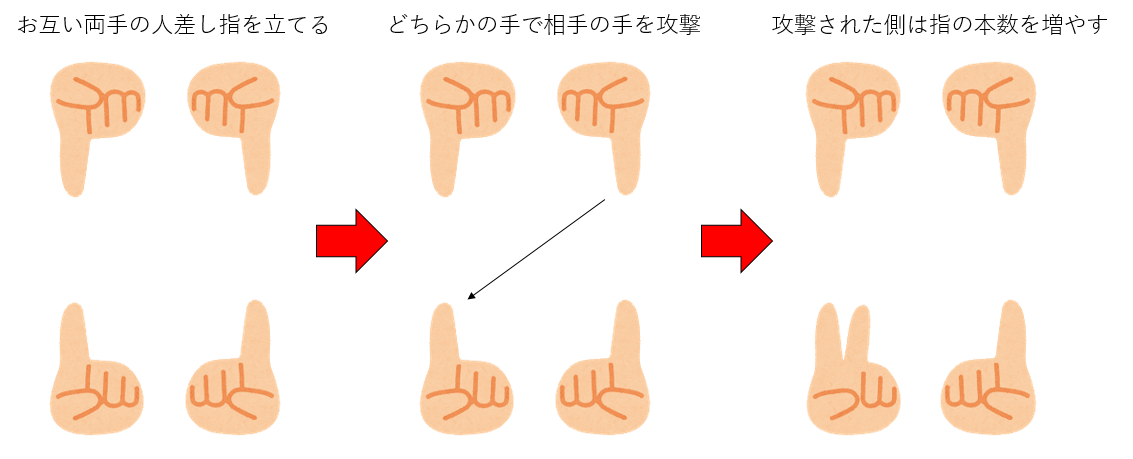
「割りばし」という二人で行う指遊びがある。地方によって名前やルールは様々だが、基本ルールは以下のようなものだ。
- じゃんけんなどで先行、後攻を決め、お互い両手の人差し指を立てる
- 先行は、自分の好きな手で相手の好きな手を攻撃する
- 攻撃された側は、攻撃された手の指を、攻撃した手の指の本数だけ増やす
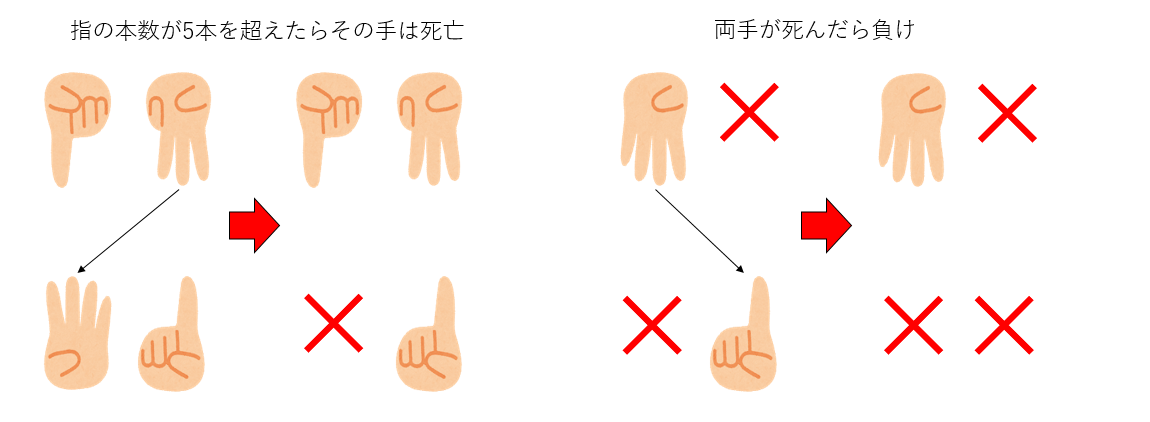
- この時、もし指が5本以上になったらその手は死ぬ
- これを交互に繰り返し、両手が死んだら負け
追加ルールやバリエーションとして、以下のようなものがある。
- modルール:攻撃されたとき、「ちょうど5」でなければ死なず、指の本数は5で割った余りになる
- 分身ルール:自分の手番で、手が一本死んでいるとき、指の総数が変わらないように両手に指を分けることができる
- 自分攻撃:自分の手で自分を攻撃することを許す
特にmodルールはかなり広い範囲で採用されているようだ。筆者の住んでいた地域では「割りばし」と呼ばれているものの、これが決定的な名前ではないらしく、ウィキペディアでは数字を増やす遊びと紹介されている。
さて、簡単のため、基本ルールだけを考えよう。死んだ手の指の本数を「5本」と数えると、お互いの指の本数は、ターン毎に必ず増加する。したがって、千日手は存在しない。また、指の本数は20本を超えることはできないため、必ず有限ターンでゲームが終わる。また、勝負が決まるのは相手の最後の手を殺した時だけなので、引き分けは存在しない。ランダム要素もないため、先手か後手のどちらかが必勝であることがわかる。
実際、このゲームは後手必勝である。このゲームを題材に、クラスを使いつつ、本格的な再帰プログラムを組んでみよう。
クラスとオブジェクト指向:課題
課題1:割り箸ゲームの状態クラスの実装とテスト
新しいノートブックを開き、waribashi.ipynbという名前をつけよ。
1. ライブラリのインポート
まず最初のセルに、後で必要となるライブラリをインポートしておこう。
import IPython
from graphviz import Digraph2. 状態クラスの実装
初期化関数
まず、割りばしゲームの「状態」を表すクラスStateを実装しよう。割りばしゲームの状態としては、先手番であるか否かis_first、先手番の指の本数f、後手番の指の本数sがある。また、「自分から遷移可能な状態」のリストも持っておこう。後で描画に必要となるので「遷移可能な状態」siblings、「この状態を描画したかどうか」is_drawnもつけておこう。2つ目のセルに以下を入力せよ。
class State:
def __init__(self, is_first, f, s):
self.is_first = is_first
self.f = [max(f), min(f)]
self.s = [max(s), min(s)]
self.siblings = []
self.is_drawn = False入力したら、インスタンスを作れることを確認しよう。3つ目のセルに以下のように入力、実行し、エラーが出なければ成功である。
s = State(True,[1,1],[1,1])確認が終わったら、3つ目のセルを削除しておくこと。
文字列変換メソッド
次に、状態を文字列に変換するメソッドを追加しよう。2つ目セルのStateクラスの__init__メソッドの後に__str__というメソッドを追加する。この時、__init__と同じインデントにすること。
class State:
def __init__(self, is_first, f, s):
self.is_first = is_first
self.f = [max(f), min(f)]
self.s = [max(s), min(s)]
self.siblings = []
self.is_drawn = False
def __str__(self):
s = str(self.f) + "\n" + str(self.s)
if self.is_first:
return "f\n" + s
else:
return "s\n" + s追加したらこのセルを再度実行してから、3つ目のセルで以下を実行せよ。
s1 = State(True,[1,1],[1,1])
s2 = State(False,[1,1],[1,1])
s3 = State(True,[3,1],[2,4])
print(s1)
print(s2)
print(s3)以下のように表示されれば成功である。
f
[1, 1]
[1, 1]
s
[1, 1]
[1, 1]
f
[3, 1]
[4, 2]上記が正しく表示されたら、3つ目のセルを消しておこう。
比較メソッド
次に、オブジェクトの比較メソッド__eq__を作ってみよう。比較メソッドとはa == bとした際に、aとbが等しいか判定するのにつかわれるメソッドだ。2つ目のセルのStateクラスの__str__の後に以下のように追加しよう。
def params(self):
return (self.is_first, self.f, self.s)
def __eq__(self, other):
return self.params() == other.params()paramsは、自分の状態をタプルとして返す関数で、__eq__は、二つのオブジェクトのparams()の返り値を比較して等しいかどうかを判定している。これを実装後、3つ目のセルで以下を実行してみよう。
s1 = State(True, [1,1],[1,1])
s2 = State(True, [1,1],[1,1])
s1 == s2結果としてTrueと出てくれば成功である。動作確認が終わったら3つ目のセルを消しておくこと。
次の状態の生成
現在の状態から次の状態を生成するメソッドを作ろう。現在の状態に対して「先手側の手の左右」と「後手側の手の左右」を選べば、次の状態が決まる。先手側の手をfi、後手側の手をsiとしよう。それぞれ0と1の値をとる変数で、0が左手、1が右手である。ただし、指の本数が大きいほうを必ず左手にするように入れ替える。例えば現在先手番で、(fi, si)==(0,0)ならば、先手が左手で後手番の左手を攻撃したという意味になり、現在後手番で(fi, si)==(0,1)ならば、後手番が右手で先手番の左手を攻撃した、という意味になる。
以上を実装してみよう。2つ目のセルのStateクラスに以下のメソッドを追加せよ。
def next_state(self, index):
fi, si = index
if self.f[fi] == 0 or self.s[si] == 0:
return None
d = self.f[fi] + self.s[si]
f2 = self.f.copy()
s2 = self.s.copy()
if d >= 5:
d = 0
if self.is_first:
s2[si] = d
else:
f2[fi] = d
return State(not self.is_first, f2, s2)追加したら、正しく実装できたか確認してみよう。3つ目のセルに以下を入力して出力を確認せよ。
s1 = State(True, [1,1],[1,1])
s2 = State(True, [1,0],[1,1])
print(s1.next_state((1,1)))
print(s1.next_state((1,0)))
print(s2.next_state((1,0)))以下のような出力が出てくれば正しく入力されている。
s
[1, 1]
[2, 1]
s
[1, 1]
[2, 1]
None最終的に2つ目のセルにあるStateクラスには、以下の5つのメソッドが実装されたはずである。
__init____str__params__eq__next_state
ここまで正しい動作が確認できていれば、確認のための3つ目のセルは削除して良い。
課題2:状態遷移図の可視化
割りばしゲームの状態遷移図(ゲーム木)を作るには、
- まず状態(ノード)が与えられた時、その状態から遷移可能な状態を生成する
- その状態が合法手であれば、自分にそれを追加する
- 追加したすべての状態について、再帰的に以上を繰り返す
という処理をすれば良い。
ただし、異なるパスで同じ状態に遷移する可能性があり、それらを「同じノード」としてまとめたいため、それをハッシュで実装する。具体的には、生成された状態の文字列をキーとしてハッシュに登録し、ハッシュに登録済みの状態ならその状態を、そうでなければ登録する、という処理を加える。
3.
関数moveの実装
「次の合法手」を探索する関数moveを3つ目のセルに入力せよ(3つ目のセルが残っていたらまず削除すること)。Stateクラスのメソッドではないことに注意。
def move(parent, is_first, nodes):
for i in [(0, 0), (0, 1), (1, 0), (1, 1)]:
child = parent.next_state(i)
if child is None:
continue
if child in parent.siblings:
continue
s = str(child)
child = nodes.get(s, child)
nodes[s] = child
parent.siblings.append(child)
move(child, not is_first, nodes)やっていることは以下の通り。
- 現在の状態から遷移可能な4状態を生成する
- それぞれが合法手であるか確認し、合法手でなければスキップ
- もしすでに自分に追加されている状態ならスキップ
- すでにハッシュ登録済みかチェック、登録済みなら登録した状態を取得、そうでないなら今作成した状態を登録する
- 親に作成したノードを追加して、そのノードを親として再帰
4.
状態木を作成する関数make_treeの実装
次に、moveに最初の状態を与えて、ゲーム木の「根(root)」を作って返す関数を作る。4つ目のセルに以下の関数を入力せよ。
def make_tree():
nodes = {}
root = State(True, [1, 1], [1, 1])
nodes[str(root)] = root
move(root, True, nodes)
return rootここまで入力したら、5つ目のセルに以下を入力して実行し、エラーがでないことを確認せよ。
root = make_tree()
print(root)最初の状態が以下のように表示されるはずである。
f
[1, 1]
[1, 1]動作確認が終わったら、5つ目のセルは消してかまわない。
5.
ゲーム木の可視化関数make_graphの実装
先ほどroot = make_tree()で作成したrootは子ノードがぶら下がっており、さらに子ノードには孫ノードが・・・と木構造を作っている。これをGraphvizで可視化しよう。
5番目のセルに、以下のプログラムを入力せよ。
def make_graph(node, g):
if node.is_drawn:
return
node.is_drawn = True
ns = str(node)
if max(node.f) == 0:
g.node(ns, color="#FF9999", style="filled")
elif max(node.s) == 0:
g.node(ns, color="#9999FF", style="filled")
else:
g.node(ns)
for n in node.siblings:
g.edge(ns, str(n))
make_graph(n, g)
return g6. ゲーム木の可視化
ここまでで上から
import文Stateクラスの宣言move関数make_tree関数make_graph関数
の5つのセルができているはずだ。それぞれが実行されていることを確認した後(不安なら再度実行した後)、一番下の6つ目のセルに以下を入力、実行せよ。
root = make_tree()
g = Digraph(format="png")
make_graph(root, g)
IPython.display.Image(g.render("test"))ここまで正しく実装されていれば、ゲーム木が表示されるはずである。青が先手勝利、赤が後手勝利である。大きすぎて見づらい場合は、右クリックから「新しいタブで画像を開く」を選ぶと見やすいかもしれない。
発展課題: 枝刈り
さて、無事にゲーム木が表示されたが、そのグラフを見ても何がなんだかわからないであろう。そこで、このゲームが後手必勝であることをプログラムで確認してみよう。
引き分けがないのだから、負けにつながる手を打たなければ勝てるはずである。先手に勝ち筋がある場合、当然先手はその手を打つ。したがって、後手は「先手に勝ち筋があるような状態につながる手」を打ってはならない。そこで、そこにつながる手を自分の子ノードリストから削除しよう。また、そうして削除していった結果、打てる手がなくなってしまうノードが出てくる(その状態になった時点で敗北確定)。このようなノードにつながる手も打ってはならないので、それも枝刈りする。こうして後手の負けにつながる枝を全て刈れば、後手必勝の手筋のみが残るはずである。
7.
枝刈り関数pruneの実装
7つ目のセルに、枝を刈るための関数pruneを実装せよ。
def prune(node):
if max(node.s) == 0:
return True
if node.is_first:
for n in node.siblings:
if prune(n):
return True
return False
if not node.is_first:
sib = node.siblings.copy()
for n in sib:
if prune(n):
node.siblings.remove(n)
if not node.siblings:
return True
return False先程のアルゴリズムの通りに実装しただけだが、再帰に慣れていないと理解しづらいかもしれない。もしわからなくても「そういうものだ」と思って今はスルーしてかまわない。
8. 枝刈り後のゲーム木の表示
8つ目のセルに、枝刈りをした後のゲーム木を表示するプログラムを書こう。
root = make_tree()
prune(root)
g = Digraph(format="png")
make_graph(root, g)
IPython.display.Image(g.render("test"))6つ目のセルの二行目にprune(root)を追加しただけなので、6つ目のセルの内容をコピペして編集しても良い。正しく実装できてれば、青い状態、つまり先手勝利の状態が消え、赤い状態しかない木、つまり後手必勝の遷移図が出てきたはずである。これを見ると、先手がどのような手を打とうとも、後手が最善手を打つと、必ず後手勝利になることがわかる。
後手必勝の確認
友人と実際にこの図に従って「割りばし」ゲームをやってみて、どのようにしても後手必勝であることを確認せよ。
余談:心理的安全性
子育てをしていると、たまに「ヒヤリ」とすることがある。いつの間にか子供が危険なもので遊んでいた、危険なものの近くにいた、ふと目を離した隙にいなくなった……そんな「ヒヤリ」としたり「ハッと」したりする、重大事故一歩手前の状態を俗に「ヒヤリハット」と呼ぶ。そんな「ヒヤリハット」をブログなどに書いた時の、まわりの人の反応を想像してみてほしい。「そんな危険な目に合わせるなんて子供がかわいそう」「○○に気をつけないなんて親として失格」という非難のコメントが付きそうな気がするであろう。このように「ヒヤリハット」を公開し、非難された親はどうするか。「次回は気をつけよう」と思う以上に「子育てのヒヤリハットはネットに公開してはいけない」と学ぶであろう。そして、そのブログの読者が「うちも気をつけよう」と思うような貴重な情報の共有機会が失われることになる。
同様なことが会社組織などで起きる。工事現場で危険な目にあったことを何気なく上長に伝えたら「危ないだろ!気をつけろ!」と叱責されたとしよう。その部下は次から危険な事例を報告しなくなるだろう。頻繁に「ヒヤリハット」が発生するということは、安全性になんらかの根本的な問題があるという重要なサインなのであるが、それを言い出しづらい雰囲気の中では「危険の芽」は黙殺され、そのうち重大事故につながってしまう。このような「ネガティブな報告」をしづらい雰囲気がまずいことは感覚的にわかるであろう。逆に、「ネガティブな報告をしても責められない、初歩的な質問をしても馬鹿にされない」状態を「心理的安全性が保たれた状態」と呼ぶ。心理的安全性(Psychological Safety)は、Googleの働き方の研究、Project Aristotleの報告から広まったものだ。
心理的安全性なしに数値目標の向上を目指すと、必ずまずい状態になる。例えば、あるソフトウェア開発グループでは、「バグゼロ」を目指し、バグの報告が多い部署は「目標達成度が低い」とみなされた。すると、当然のことながらバグを見つけてもそれはバグとして報告されず、例えば「機能追加の要望」などとして処理されるようになった。数字の上では全体的に「報告される」バグの数は激減したが、これが望ましい状態ではないことは明らかであろう。逆に、ある工場では、製品の完成チェック時に必ず一定数以上の問題を見つけることを強制した。すると品質管理部は、たとえほとんど問題がない製品でも言いがかりのような問題を見つけて報告するようになり、工場ではそれに対抗して、わざと目に付きやすい問題点を残すようになった。「バグが許されない職場」は「バグが報告されない職場」になり、「問題を必ず見つける職場」では「問題を必ず作る職場」になってしまった。
共通するのは心理的安全性であり、もっと言えばチームの目的意識の共有である。我々は本質的なバグの数を減らしたいのであって、バグの報告を減らしてはならない。「心理的安全性なしに数字のみを重視すると、必ず数値ハックされる」ということは心に留めておきたい。