Pythonが動く仕組み
本講で学ぶこと
- プログラムの実行の仕組み
- 抽象構文木とバイトコード
コンピュータはどうやって動くのか
車を運転していない人でも、「車はガソリンという可燃性の液体を燃料とし、それを噴射して点火、爆発させてピストンを動かし、そのピストンの運動を回転運動に変換してタイヤに伝えて動いている」、ということはぼんやりと知っていることだろう。この知識は、車を運転するときにはあまり必要ない。実際、よほど車好きでない限り、車の運転をする際にエンジンやトランスミッションの仕組みを意識することはないであろう。しかしそれでも、車の仕組みは簡単に知っておくべきだと筆者は思う。冷蔵庫や電子レンジ、これらの家電は、その動作原理を知らずとも使うことは可能だし、おぼろげに原理を知っているからといってあまり役に立つ気はしないが、やはりざっくりとは知っておくべきである。それが教養というものだ。コンピュータの動作についても同様である。
これまで、ブラウザ上でプログラムを入力し、実行させ、その結果を表示させてきた。Pythonのプログラムはクラウド上で実行されたが、そのブラウザを実行しているのは皆さんの目の前にあるのはコンピュータである。コンピュータとはcomputeするもの、つまり計算機であり、何かしら計算してその結果を表示することを繰り返す機械である。では、そもそもプログラムとはどうやって動いているのだろうか?そのようなことを知っていても今後の人生の役には立たないと思うが、せっかくプログラミングを覚えるのだから、計算機がどういう仕組みで動いているのか知っておいても良いだろう。
機械語
いま、目の前にある計算機は、ディスプレイ(表示装置)、キーボードやマウス(入力装置)、CPU(中央演算処理装置)、メモリ(記憶装置)などから構成されている。ディスクなどのストレージやネットワークなどの通信装置については今は忘れよう。このうちCPUがもっとも重要な装置であるが、やっていることは単純であり、
- メモリから命令とデータを取ってくる
- 命令を解釈し、データを演算器に投げる
- 演算器から返ってきた結果をメモリに書き戻す
という一連の動作をひたすら繰り返しているに過ぎない。「命令」も一種のデータであり、メモリに置いてあることに注意しよう。演算器というのは、文字通り演算する機械である。例えば足し算をしたければ加算器を、掛け算をしたければ乗算器が必要になる。また、整数演算と浮動小数点演算は全く異なる演算器を用いる。
さて、計算機が解釈できるのは数字だけであるため、機械には数字列を使って命令を行う。この数字列による言葉を 機械語 (machine language)と呼ぶ。コンピュータとは計算機であり、計算とはデータに四則演算などの演算をすることである。したがって、計算機に何か計算させたければ「何を(データ)」「どうするか(命令)」がセットである必要があることがわかるだろう。機械語というと難しそうだが、結局のところ「何を」「どうするか」を羅列しているに過ぎない。
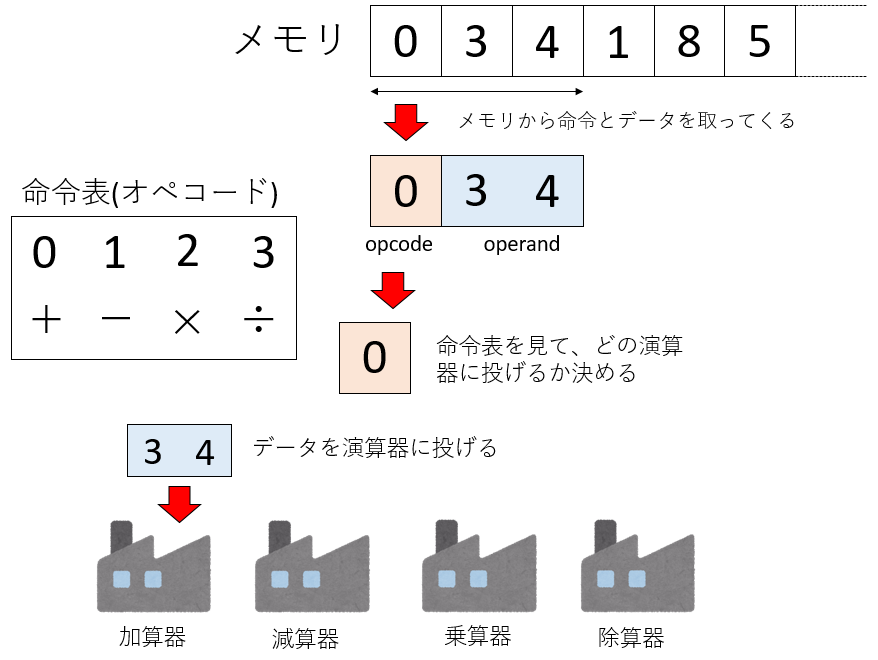
例えば一桁の整数を二つ受け取って四則演算をする計算機があったとしよう。四則演算をするので、演算は加算、減算、乗算、除算の4種類である。なのでそれぞれに0,1,2,3の数字を割り当てよう。四則演算をするには、整数が二つ必要だ。その数字も並べよう。例えば「034」という数字列は「3+4」を、「185」は「8-5」を表す。計算機は、メモリから三つの数字をとってきて、最初の数字を見て「どの演算器に投げるか」を決める(命令を最初に置いたのはそのためだ)。そして続く二つのデータを演算器に投げる。かなり単純化されているが、これが機械語である。このように、「何をするか」を表す部分をオペコード(operation code, opcode)、「データ」を表す部分をオペランド(operand、被演算子)と呼ぶ。
プログラム言語とコンパイラ
さて、計算機が解釈できるのは機械語だけである。機械語は難しくはないが、「足し算は0で・・・」と覚えるのは面倒だ。そこで「034」という数字の羅列の代わりに「ADD 3,4」という書き方をしよう。これを「034」に変換するのは簡単だし、人間が見て「3と4を足すんだな」とわかりやすい。このように機械語と一対一対応する言語をアセンブリ言語(assembly language)と呼ぶ。しかし、アセンブリ言語でもまだ面倒だ。もっと、人間にわかりやすい形式、先ほどの例なら「3+4」と書いて、それを計算機が理解できる形式に変換したい、と思うのは自然であろう。その「人間が理解できる形式」がプログラム言語と呼ばれるものである。
プログラム言語は人間にわかりやすい形式になっているが、そのままでは機械は理解できない。そこで、プログラムを機械語に「翻訳」する必要がでてくる。この翻訳作業をするのがコンパイラである。一口に「翻訳」と言っても、コンパイラがやるべき仕事は多い。まず「3 + 4」というひと続きの文字列が与えられたときに、「3」「+」「4」という文字に分割しなければならない。これを字句解析(lexical analysis)と呼ぶ。さらに、「3と4は整数であり、+という演算子の引数である」と認識する必要がある。これが構文解析(syntax analysis)と意味解析(semantics analysis)である。この構文解析を行うのがパーサ(parser, 構文解析器)である。パーサは、プログラムを抽象構文木 (abstract syntax tree, AST)と呼ばれるデータ構造に変換する。
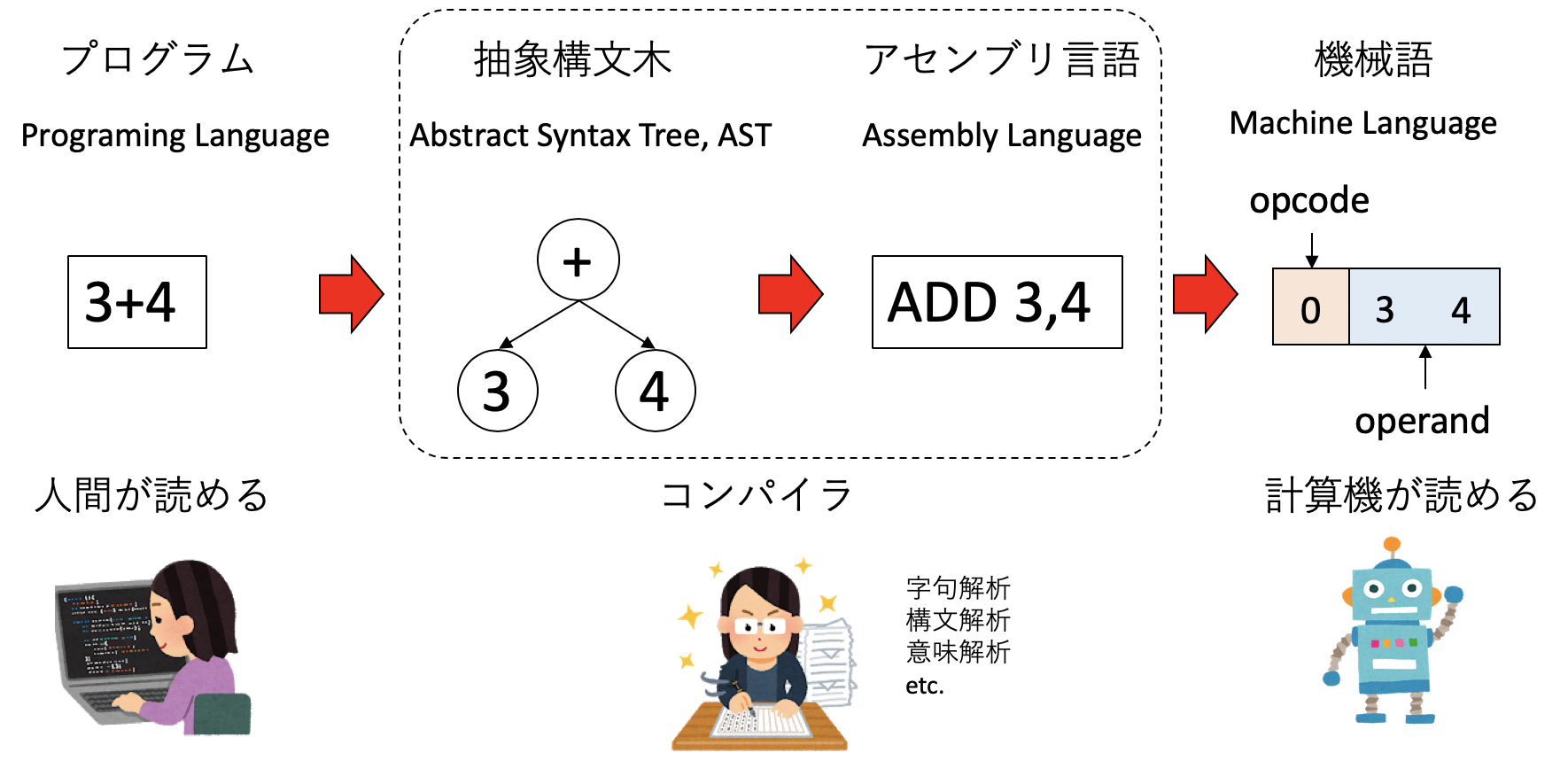
パーサによって抽象構文木が与えられたら、そこからアセンブリコードを生成する。通常は途中で中間コードを生成し、その後にアセンブリ言語に変換する。アセンブリを実行ファイルにするためには、さらに「リンク」という作業工程がある。リンクを行うのがリンカ(linker)というプログラムで、これもかなり複雑なことをしているのだが、本書では扱わない。
最初に、プログラム言語には大きく分けてコンパイル言語とインタプリタの二種類があることに触れた。プログラムをコンパイラが機械語に翻訳し、そのまま実行するのがコンパイル言語であり、C++などはコンパイル言語の代表格的な言語である。
一方、プログラム言語を逐次的に解釈して実行するのがインタプリタ言語であり、Pythonもインタプリタ言語に属す。しかし、プログラムをそのまま解釈しながら実行すると遅いため、多くのインタプリタ言語はバイトコード(bytecode) と呼ばれる中間コードを生成し、それを実行することで高速化を図る。
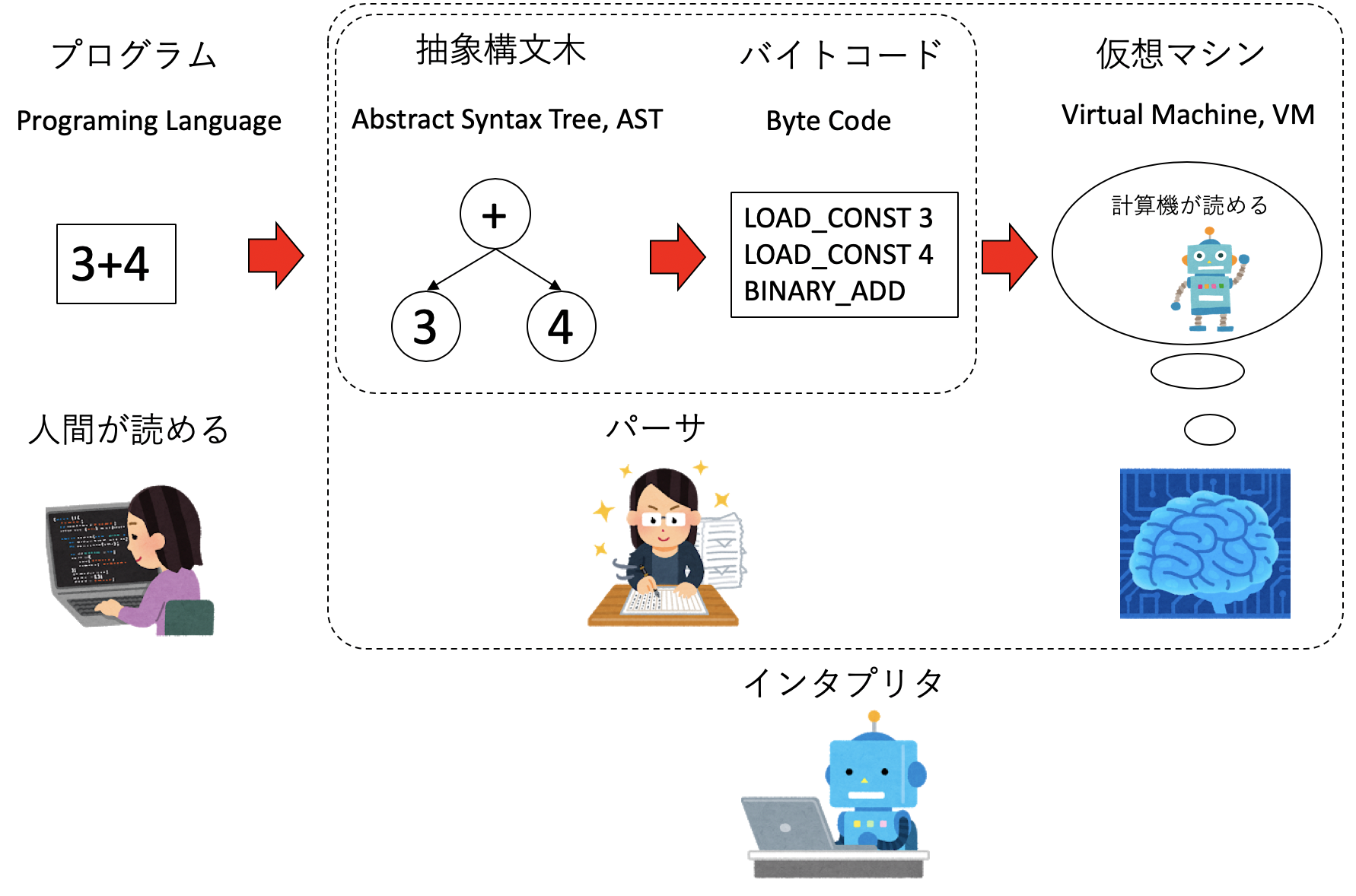
Pythonは、まずプログラムを抽象構文木に変換する。その後、その構文木からバイトコードを生成する。バイトコードは仮想的な機械語である。機械語は、現実に存在する機械で動作するが、バイトコードは仮想的な機械向けの機械語である。このバイトコードを実行するプログラムを仮想マシン(Virtual Machine, VM)と呼ぶ。「エミュレータ」という言葉を聞いたことがあるかもしれない。昔のゲームハード用のゲームを、現在のゲームで実行するのに使われたりする。仮想マシンは、実際には存在しないハードウェアであるが、それを現実の計算機でエミュレートすることでプログラムを実行する。
本講ではPythonが動く仕組みを理解するため、実際に抽象構文木とバイトコードを見てみることにしよう。
バイトコードとスタックマシン
Pythonは、与えられたプログラムを、仮想的なアセンブリであるバイトコードに変換し、それを仮想マシン上で実行する。Pythonの仮想マシンは、メモリとしてスタックを用いる。
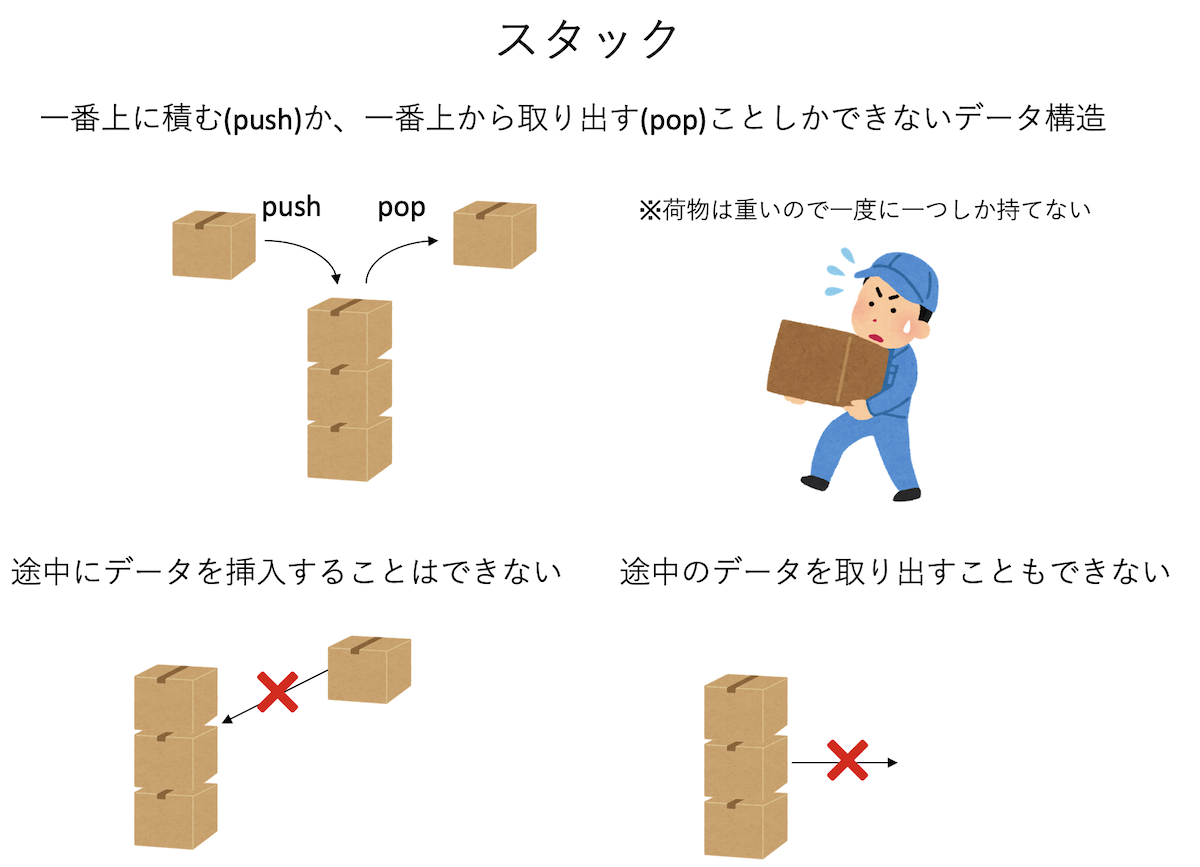
スタック(stack)とは、データ構造の一つである。重い荷物を積み上げたような状態を想像せよ。荷物は重いので、一度に一つしか持ち上げることができない。従って、「手持ちの荷物を一番上に積む」か「一番上の荷物を取り出す」ことしかできず、積み上がった荷物の途中に別の荷物を入れたり、一番上ではない荷物を取り出すこともできない。新しい荷物を一番上に載せることをプッシュ(push)、積み上がった荷物の一番上にあるものを取り出すことをポップ(pop)と呼ぶ。
スタックでは「入った順番」と「出る順番」が逆になっている。これを「後入れ先出し」の意味でLast In First Out (LIFO)と呼ぶ。逆に、「最初に入った人が最初に出てくる」ようなデータ構造は「先入れ先出し」の意味でFirst In First Out (FIFOと呼び、このような振る舞いをするデータ構造をキュー(queue)と呼ぶ。
Pythonはの仮想マシンは、スタックにデータをプッシュしたりポップしたりすることでプログラムを実行する。たとえば3 + 4というプログラムは、
LOAD_CONST 0 (3)
LOAD_CONST 0 (4)
BINARY_OP 0 (+)というバイトコード列に変換される。
LOAD_CONST 3は、スタックに「3」をプッシュせよ、という意味である。また、演算は、必要な数だけスタックからデータをポップして行う。例えばBINARY_OPは、「スタックから二つデータをポップし、指定した演算(今回は加算)を適用した結果をまたスタックにプッシュせよ」という命令だ。以上の結果、スタックの一番上には演算結果である7がプッシュされる。
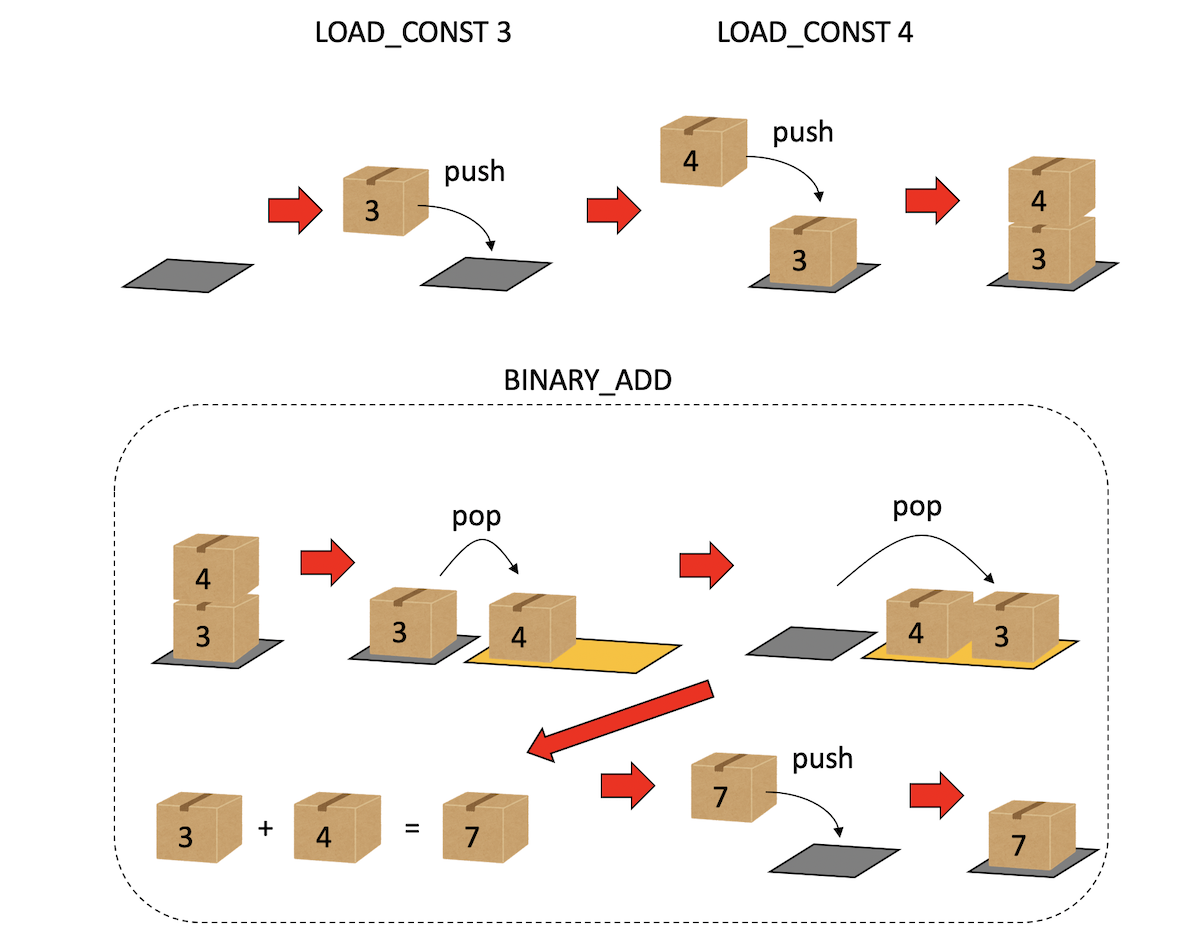
このように、メモリとしてスタックを用いるような計算機をスタックマシン (stack machine)と呼ぶ。Pythonの仮想マシンはスタックマシンである。
既にみたように、スタックのデータのやりとりは「一番上」のみ、取り出せるデータも「最後に入れたもの」だけに限られ、途中にデータを挿入することも、任意の場所のデータを取り出すこともできない、いわば「不自由」なデータ構造である。なぜこのような「不自由」なデータ構造をメモリに採用しているかというと、命令セットが簡単になるというメリットがあるからである。
我々が通常使っている計算機は「レジスタマシン」と呼ばれる方式を採用している。レジスタマシンは、レジスタという計算を行うための小さく高速な作業領域を複数持ち、メモリも任意の場所に読み書きできる。すると、当然のことながら「メモリのどこから、どのレジスタに値をロードし、計算結果をどこに書き込むか」を指定しなければならない。それに対して、スタックマシンはメモリの「入り口」と「出口」が決まっているため、例えば足し算をする命令BINARY_ADDは引数を必要としない。このように、スタックマシンは命令セットが単純になるというメリットがあり、仮想マシンのモデルとして広く採用されている。
逆ポーランド記法
さて、先程見たように、3 + 4というプログラムは、
LOAD_CONST 0 (3)
LOAD_CONST 0 (4)
BINARY_OP 0 (+)という命令列に変換された。ここで、LOAD_CONSTは省略し、かつBINARY_ADDを+で表記すると、この命令列は3 4 +と表現できる。このように、演算子が、被演算子の後ろに置かれる記法を後置記法、もしくは逆ポーランド記法(Reverse
Polish Notation,
RPN)と呼ぶ。我々が普段目にする3 + 4という記法は、演算子が被演算子の中に置かれるため、中置記法と呼ばれる。
逆ポーランド記法は、スタックマシンと相性が良い。3 4 +という命令列が来た時、それを一つ一つの区切り(
トークン(token)
と呼ぶ)に分解して、
- もしトークンが数字ならスタックにプッシュ
- もしトークンが演算子なら、スタックから二つデータを取り出して演算、結果をスタックにプッシュ
とするだけで計算が実行できる。
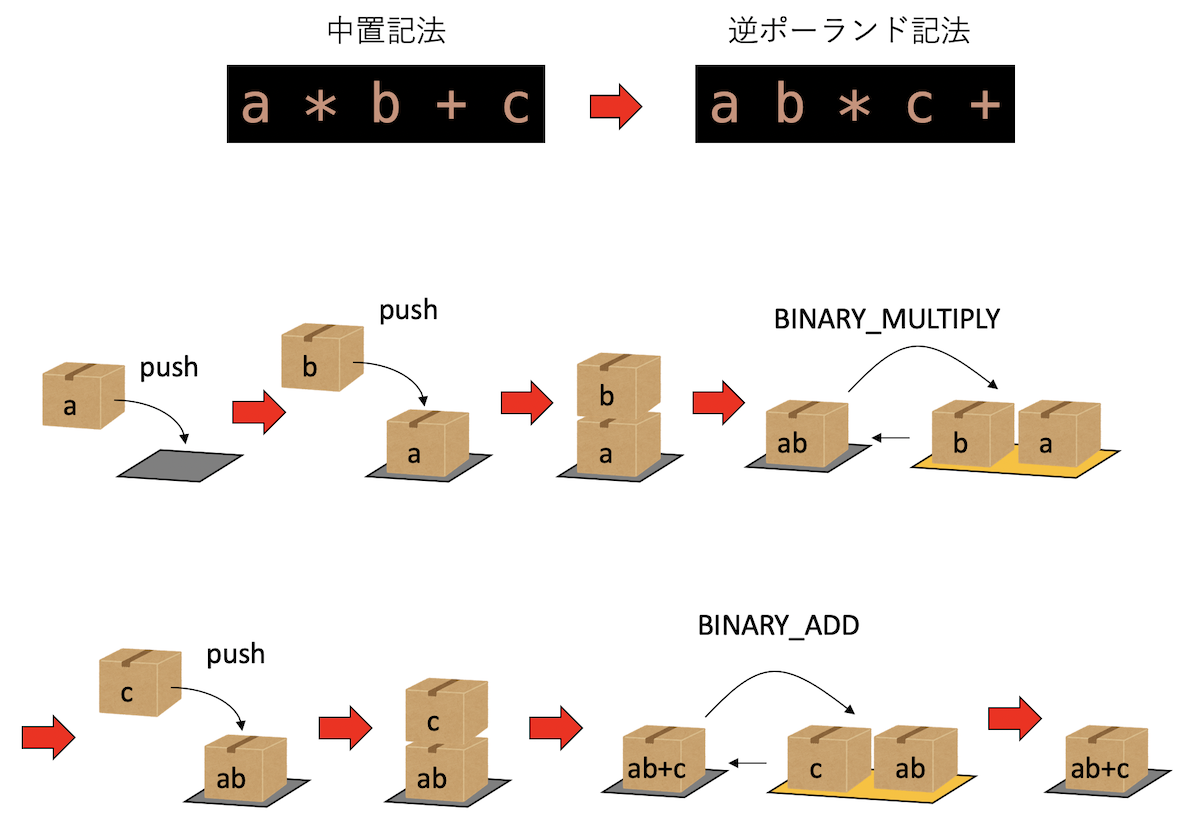
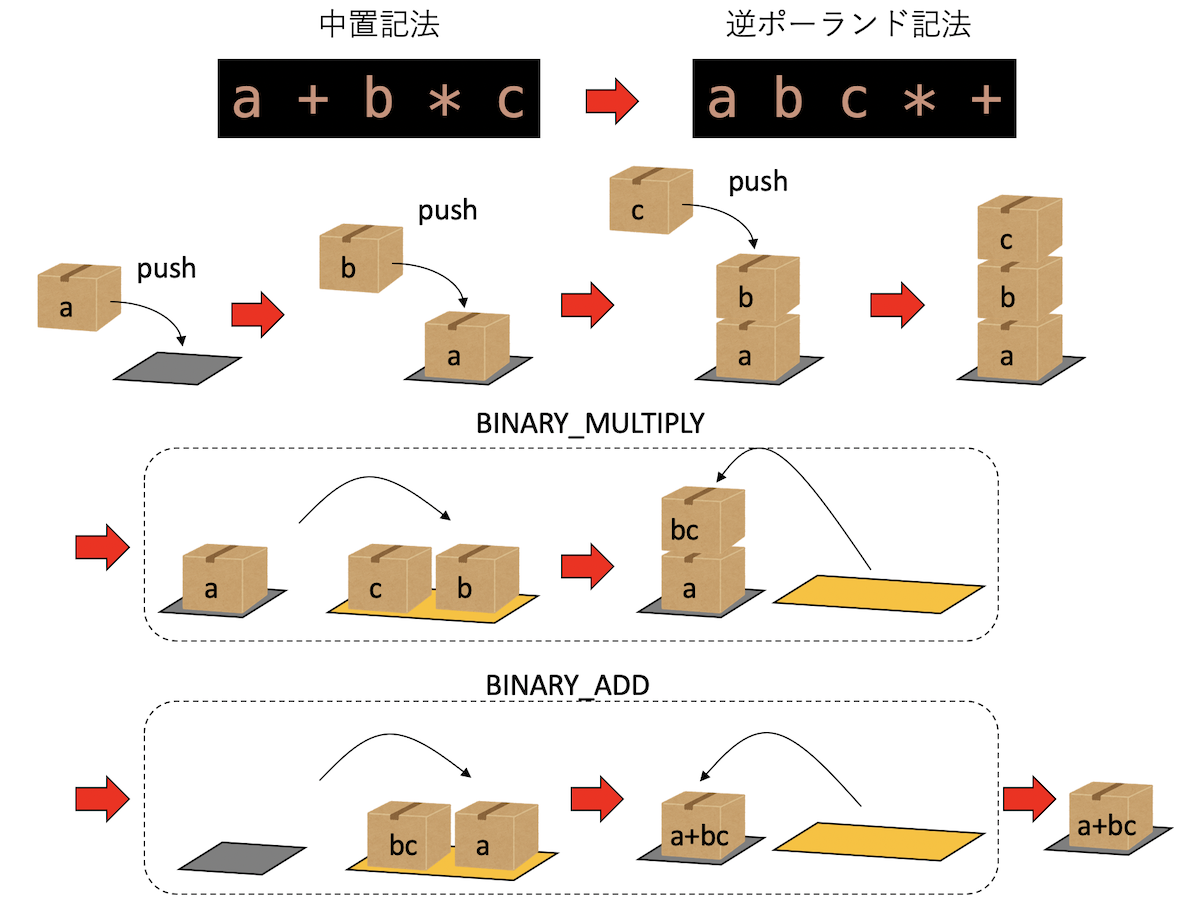
例えば、a * b + cという計算は、逆ポーランド記法ならa b * c +と表記できる。また、a + b * cの場合、先にb * cを実行する必要があるが、逆ポーランド記法ならa b c * +と表記され、演算子の優先順位を気にすることなく順番に処理すれば良い(より正確には、演算子の優先順位を考慮して逆ポーランド記法を構成する)。
実際にPythonのバイトコードが逆ポーランド記法になっているのを見てみよう。バイトコードを表示するにはdisをインポートする。
import disこの状態で、
dis.dis("a * b + c")を実行すると、
0 0 RESUME 0
1 2 LOAD_NAME 0 (a)
4 LOAD_NAME 1 (b)
6 BINARY_OP 5 (*)
10 LOAD_NAME 2 (c)
12 BINARY_OP 0 (+)
16 RETURN_VALUEとなり、これがa b * c +に対応しているのがわかるであろう。
また、
dis.dis("a + b * c")を実行すると
0 0 RESUME 0
1 2 LOAD_NAME 0 (a)
4 LOAD_NAME 1 (b)
6 LOAD_NAME 2 (c)
8 BINARY_OP 5 (*)
12 BINARY_OP 0 (+)
16 RETURN_VALUEとなる。これがa b c * +になっていることは見てわかるであろう。
Pythonはどうやって動くのか:課題
課題1-1:抽象構文木の可視化
Pythonのプログラムが抽象構文木に変換される様子を観察してみよう。新しいノートブックを開き、ast.ipynbとして保存せよ。
1. ライブラリのインポート
最初のセルで必要なライブラリをインポートする。
import ast
import dis
import IPython
from graphviz import Digraph2. 抽象構文木をグラフに変換する関数
2つ目のセルに抽象構文木を解析してグラフに変換する関数visitを書く。
def visit(node, nodes, pindex, g):
name = str(type(node).__name__)
index = len(nodes)
nodes.append(index)
g.node(str(index), name)
if index != pindex:
g.edge(str(pindex), str(index))
for n in ast.iter_child_nodes(node):
visit(n, nodes, index, g)__name__は前後にアンダースコアが二つずつであることに注意。
3. グラフを可視化する関数
3つ目のセルに抽象構文木をグラフとして可視化する関数show_astを書く。
def show_ast(src):
graph = Digraph(format="png")
tree = ast.parse(src)
visit(tree, [], 0, graph)
img = graph.render("test.png")
return IPython.display.Image(img)ast.parseは、引数として与えられた文字列をPythonのプログラムとして解釈し、抽象構文木に変換する。返り値は、構文木の根(root)である。それをast.iter_child_nodesに渡すと、そこにぶら下がるノードが返ってくるので、それらすべてに対してfor文をまわして、子ノードに対して再帰的にvisitを呼び出し、子孫ノードを取得していく、というのがこのコード(visit及びshow_ast関数)の仕組みである。
4. 抽象構文木の表示
ここまで作成した関数を使って、プログラムの抽象構文木を表示させて見よう。解析したいソースコードをsrcという文字列に代入し、show_ast(src)を呼ぶことで抽象構文木を表示することができる。
src="""
3+4
"""
show_ast(src)ここでsrc=の後、及びshow_astの前に"(ダブルクォーテーションマーク)が三つ続いていることに注意。
ここまで正しく入力されていれば、抽象構文木のグラフが表示されるはずである。うまくできたら、パースするプログラム文字列を変え、別のプログラムをパースしてみよ。まずは3+4の+を-に変えてみよ。次に、以下のプログラムをパースせよ。
a, b = (1,2)def func(a,b):
return a+b上記のプログラムを入力するには、"""で囲まれた領域に入力すること。例えば最初の例なら、
src = """
a, b = (1,2)
"""と入力する。抽象構文木とプログラムの対応がわかるだろうか?
課題1-2:バイトコード
5. バイトコードの表示
以下のプログラムを実行し、バイトコードが得られることを確認せよ。
dis.dis("a + b")バイトコードが得られたら、以下のプログラムに対応するバイトコードを出力し、逆ポーランド記法に対応していることを確認せよ。
a + b + ca + b * c
課題2-1:逆ポーランド記法電卓
最も簡単なスタックマシンの例として、逆ポーランド記法による計算機を実装してみよう。逆ポーランド記法とは、「3 + 4」を「3 4 +」と表記する方式だ。人間には読みづらいが、電卓を実装しやすい、という特徴がある。
具体的には、以下のような「プログラム」を組む。
- プログラムは、整数、‘+’、`-’の三種類のトークンで構成される
- プログラムを一つ読み込み、以下の動作をする
- プログラムが演算子なら、スタックから二つデータをポップして、計算し、結果をプッシュする
- 整数なら、そのままスタックにプッシュする
- プログラム終了時、スタックの一番上にある数字を表示して終了する
新しいノートブックを開き、calc.ipynbとして保存せよ。
1. ライブラリのインポート
まずは必要なライブラリをインポートしておこう。
import dis2. 計算機の実装
では計算機のプログラムを記述しよう。まずは加減算のみに対応させる。最初のセルに以下を入力せよ。
def calc(code):
data = code.split()
stack = []
for x in data:
print(stack, x, end=" => ")
if x == '+':
b = stack.pop()
a = stack.pop()
stack.append(a+b)
elif x == '-':
b = stack.pop()
a = stack.pop()
stack.append(a-b)
else:
stack.append(int(x))
print(stack)
print(stack.pop())2. 計算のテスト
実際に計算してみよう。2つ目のセルで以下を実行せよ。
calc("1 2 +")以下のような実行結果が得られたはずである。
[] 1 => [1]
[1] 2 => [1, 2]
[1, 2] + => [3]
3これは、
- 最初はスタックが空
[]で、そこに1が来たのでプッシュされて[1]になった - 次に
2が来たので、それもプッシュしてスタックの状態が[1,2]になった - 次に
+が来たので、スタックから値を二つ取り出し、その和をプッシュして[3]になった - 実行すべきプログラムがなくなったので、スタックの一番上にある数字
3を表示して終了
という処理内容を表している、
課題2-2: 乗算、除算の実装
作成した電卓に、乗算と除算を実装せよ。ただし、除算に関しては、入力プログラムとしては/を入力するが、実際の処理(stack.append)では//を実行することで、実行結果を整数にすること。
ヒント:
calc関数にelif文を追加し、xが*や/の場合の処理を追加する。
以下の「プログラム」に対して、以下のような実行結果が得られれば正しく実装できている。
calc("1 2 + 3 * 4 /")[] 1 => [1]
[1] 2 => [1, 2]
[1, 2] + => [3]
[3] 3 => [3, 3]
[3, 3] * => [9]
[9] 4 => [9, 4]
[9, 4] / => [2]
2発展課題: 中置記法から逆ポーランド記法への変換
disを用いてバイトコードを出力することで、中置記法の計算式を逆ポーランド記法に変換できる。
例えば、1 + 2 * 3の例なら
dis.dis("a + b * c")を実行すると、
0 0 RESUME 0
1 2 LOAD_NAME 0 (a)
4 LOAD_NAME 1 (b)
6 LOAD_NAME 2 (c)
8 BINARY_OP 5 (*)
12 BINARY_OP 0 (+)
16 RETURN_VALUEという表示が得られる。ここから、a,b,cを1,2,3に変換し、バイトコードの順番どおりに”
1 2 3 *
+“と並べれば、1 + 2 * 3の逆ポーランド記法が得られる。なお、dis.disに数字ではなくアルファベットを入力するのは、最適化により計算されてしまうことを防ぐためだ。
同様にして、以下の中置記法の計算式を逆ポーランド記法に変換し、先程実装した計算機で実行し答えが合っていることを確かめよ。演算子の優先順位も考慮すること。
1 + 2 * 3 - 4(1 + 2 * 3) / 4
余談:機械がやるべきこと、やるべきでないこと
今でこそ「面倒な単純作業は人間ではなく機械にやらせるべき」という考えが(たぶん)浸透しているが、昔は計算機は非常に高価であり、その計算時間は貴重な資源であった。アセンブリを機械語、つまり数字の羅列に変換するのを「アセンブル」と呼ぶが、それを人間が手で行うことを「ハンドアセンブル」と言う。計算機が使われ始めた当初は、もちろんアセンブラなどなかったから、みんなハンドアセンブルをしていた。さて、世界で初めてアセンブラを作ったと思われているのはドナルド・ギリース(Donald B. Gillies)である。1950年代、ギリースは、フォン・ノイマンの学生だった時、アセンブリを機械語に自動で翻訳するプログラムを書いていた。ギリースがアセンブラを書いているのをフォン・ノイマンが見つけたときのことを、ダグラス・ジョーンズという人が以下のように紹介している。
John Von Neumann’s reaction was extremely negative. Gillies quotes his boss as having said “We do not use a valuable scientific computing instrument to do clerical work!” (I wish I could reproduce Gillies’ imitation of Von Neumann’s Hungarian accent, he was very good at it!)
(筆者による訳)
ノイマンの反応は極めてネガティブだった。ギリースはボス(ノイマンのこと)の口真似をしながらこう言った「我々は貴重な科学計算機をそのようなつまらない仕事に使うべきでない!」 (ギリースの口真似を再現できたらと思う。彼はフォン・ノイマンのハンガリー訛りの英語の真似がすごく上手いんだ)
現在、「AIが人間を超える(シンギュラリティ)」とか「AIにより人間の仕事が奪われる」とかいった、一種の終末思想が盛んに喧伝されている。私はAIの専門家ではないので、将来どうなるかはわからない。しかし、AIは人間が作るものである。自動車が普及することで運転手という職業ができたように、「AIが人間の可能性を奪う」という「引き算の考え」よりは、「AIと人間の組み合わせで新たな可能性が生まれる」と「足し算の考え」でポジティブに考えたい。おそらくそのほうが生産的であろう。
参考URL:
https://groups.google.com/forum/#!msg/alt.folklore.computers/2fdmW2PU8dU/OJ_-6BjoP0YJ