リストとタプル
本講で学ぶこと
- リスト
- タプル
- 値のコピーとリストのコピーの違い
- 参照の値渡し
- リスト内包表記
リスト
プログラムを組んでいると、何かひとまとまりのデータをまとめて保持し、処理したい場合がある。 そのようなデータ構造を表現するのがリスト(list)である。他の言語では配列(array)と呼ばれることもある。
リストは[]の中に、カンマで区切って表現する。例えば、
[1,2,3]とすると、整数の1,2,3を含むリストができる。
また、
["A","B","C"]とすると、文字列のリストができる。リストにはどんなものも入れることができる。また、異なる種類のものを混ぜて入れることもできる。
["A", 1, 1.0]変数にリストを代入することもできる。
a = [1, 2, 3]リストの要素には、[]でアクセスできる。例えばaの最初の要素が欲しい場合はa[0]とする。カッコの中の数字を
添え字(index)
と呼ぶ。言語によって、添え字が0始まりの場合と1始まりの場合がある。Pythonは0始まりである。
a = [1,2,3]
a[0] # => 1要素に値を代入することができる。
a = [1,2,3]
a[1] = 4
a # => [1,4,3]リストは入れ子にすることもできる。
a = [[1,2],[3,4],5]入れ子になったリストは、添え字を複数指定することで要素を得ることができる。
a = [[1,2],[3,4],5]
a[0] # => [1,2]
a[0][1] # => 2リストの長さはlenという関数で取得できる。
a = [1,2,3]
len(a) # => 3二つのリストを結合することができる。
[1,2] + [3,4,5] # => [1,2,3,4,5]要素を追加する場合はappendを使う。
a = [1,2]
a.append(3)
a # => [1,2,3]リストをappendする場合には注意が必要である。
a = []
b = [1,2]
a.append(b)
a.append(b)とすると、見かけ上aは2行2列の行列のように見える。
print(a) # => [[1, 2], [1, 2]]しかし、要素に含まれる二つのリストは同じものであるから、一方を修正するともう一方も影響を受ける。
a[0][0] = 4
print(a) # => [[4, 2], [4, 2]]なぜこうなるかは、後述する「リストのメモリ上での表現」を知れば理解できるであろう。
リストに要素が含まれるかどうかは、inで調べることができる。
a = [1,2,3]
1 in a # => True
4 in a # => Falseリストの要素を順番に取り出しながら、すべての要素について処理をしたい場合、forとinを使う。
a = ["A", "B", "C"]
for i in a:
print(i)タプル
タプル(tuple)
は、複数の値の組を表現するデータ構造である。タプルはカンマで区切られた値で表現されるが、紛らわしいときには丸カッコ()で囲む。
a = 1, 2, 3
a # => (1, 2, 3)タプルはリストと同様にlenで長さを得たり、添え字で要素を得ることができる。
a = 1, 2, 3
a[0] # => 1
len(a) # => 3タプルの結合もできる。
(1,2) + (3,4) # => (1,2,3,4)このようにタプルはリストに似ているが、一度作成されたタプルは修正できない。
a = (1, 2, 3)
a[1] = 4 # => 'tuple' object does not support item assignmentタプルは関数で複数の値を返したい場合によく使われる。
def func():
return 1, 2
func() # => (1,2)タプルを使って、複数の変数を一度に初期化することができる。
a, b = 1, 2
a # => 1
b # => 2以下のようにすると、変数の値の交換ができる。
a, b = b, aタプルのリストを作ることもできる。
a = [(1,2), (3,4)]その場合、例えば0番目の要素を以下のように変数に代入できる。
a = [(1,2), (3,4)]
x, y = a[0] # x = 1, y = 2になるenumerate
for x in a:という構文で、リストaのそれぞれの要素xについて処理をすることができる。しかし、たまに「要素の値」と、「その要素がリストの何番目にあるか」の情報が両方欲しい場合がある。その時に使うのがenumerateだ。リストaについて、enumerate(a)とすると、要素のインデックスと要素の内容をペアで受け取ることができる。
例えば、こんなことができる。
a = ["A", "B", "C"]
for i, x in enumerate(a):
print(i, x)ここでは、インデックスをiで、要素をxで受け取っている。実行結果はこうなる。
0 A
1 B
2 Cリストとタプルについて覚えて起きたいことは他にもいろいろあるが、それは必要に応じて説明していくことにしよう。
メモリ上でのリストの表現
さて、リストがメモリ上でどのように表現されているか見てみよう。すでに、「変数とはラベルである」と学んだ。これはリストにおいても変わらないが、リストは複数の要素を含むため、リストを表すラベルは「リストの先頭位置」を指す。
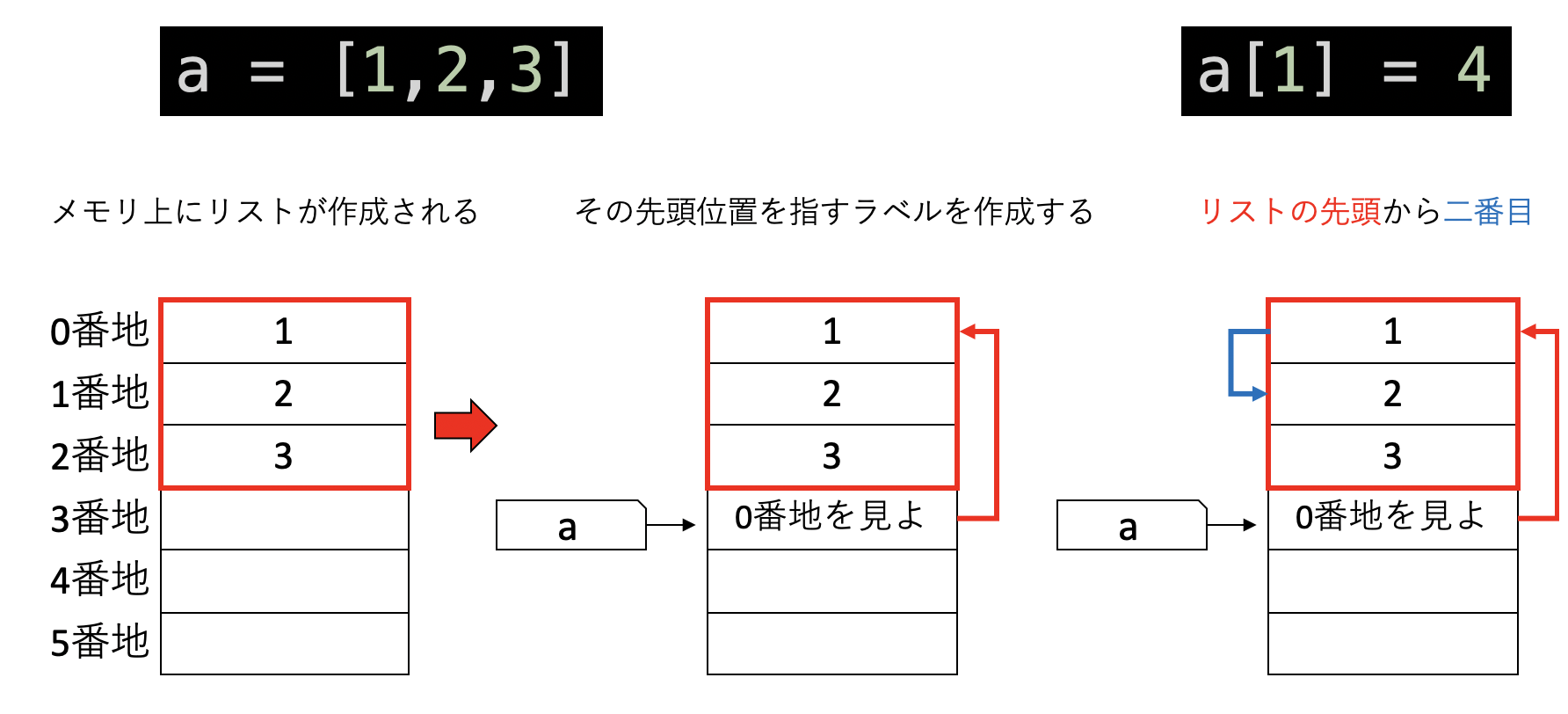
例えば、a = [1, 2, 3]という命令を見てみよう。これは、
- メモリ上に
[1, 2, 3]というリストを作成し、 - その先頭位置を指す場所を作成して、そこに
aというラベルをつける
という操作から構成される。ここで、aが「リストの先頭そのもの」ではなく、「リストの先頭を指す場所」を指していることに注意。この仕様から、リストをコピーする際には注意が必要となる。
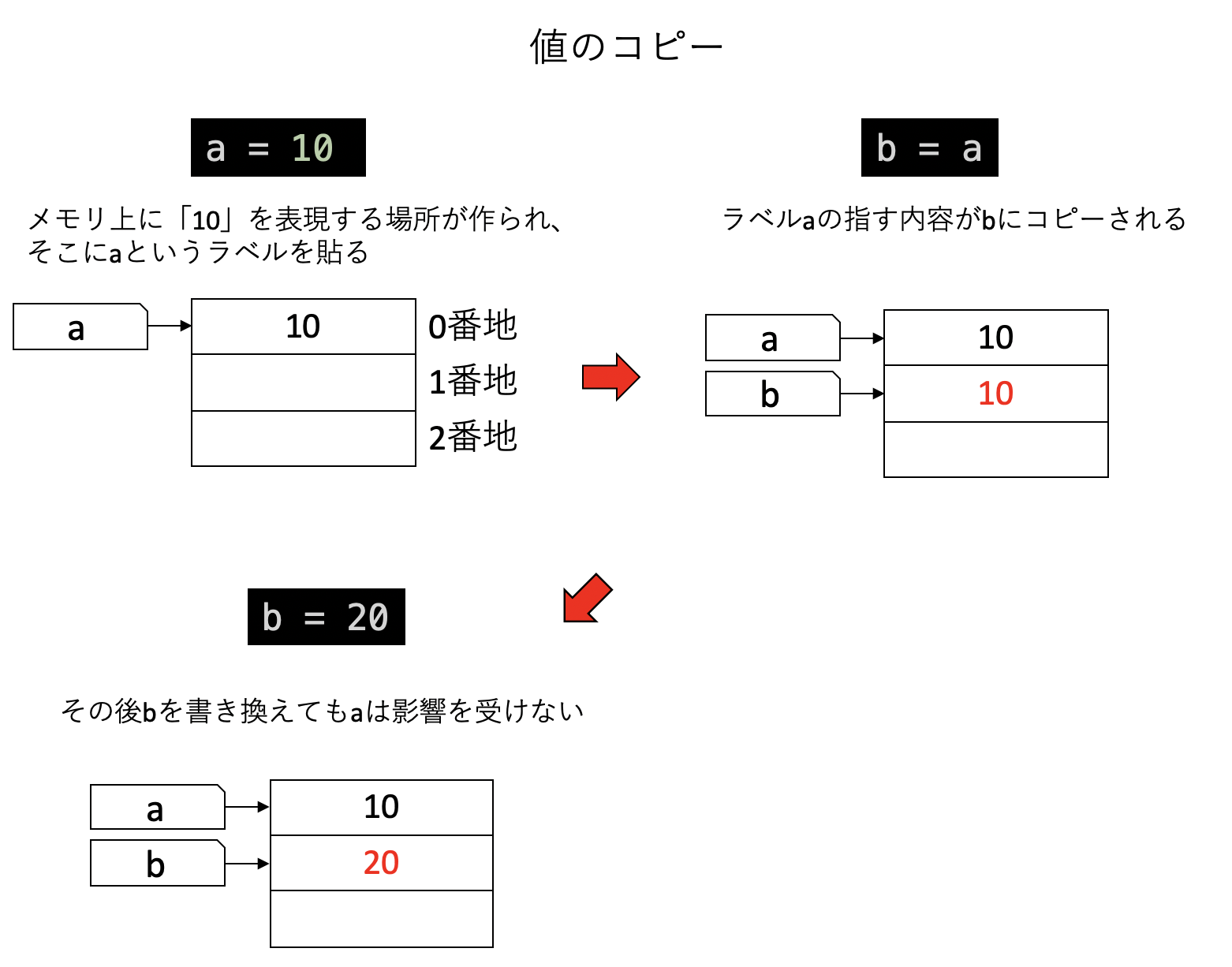
まず、普通の変数のコピーを見てみよう。例えば10という値を指す変数aをbにコピーし、その後bに20を代入する操作を考える。
a = 10
b = a
b = 20この時、
a = 10:メモリ上に「10」を表現する場所が作られて、そこにaというラベルを貼るb = a:aの指す値をコピーしてから、そこにbというラベルを貼るb = 20:bの指す値を20に書き換える
という操作が行われている。
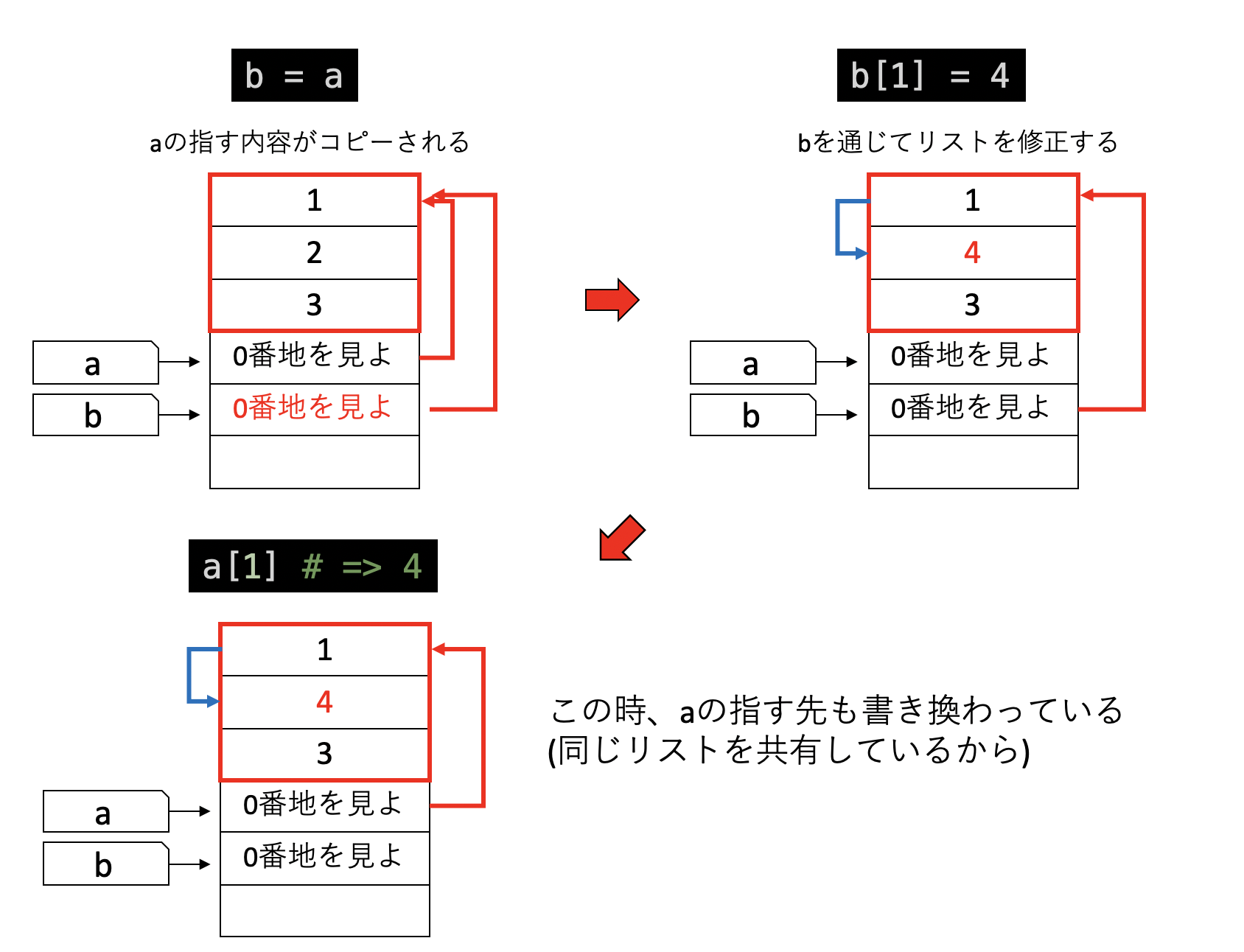
次に、リストのコピーを見てみよう。[1, 2, 3]というリストを指す変数aをbにコピーし、その後b[1] = 4と、リストを修正する操作を考える。すると、実際にはコピー元のaが指すリストも修正されている。この操作のメモリ上での表現を見てみよう。
まず、b = aとして他の変数にリストをコピーすると、整数等の場合と同様に、「ラベルの指している場所の値をコピーして、そこにラベルを貼る」という操作が行われる。この時コピーされるのは「リストの先頭の場所」という情報であるから、aとbのラベルは同じリストを指すことになる。したがって、bを通じてリストを修正すると、aが指すリストも修正されることになる。
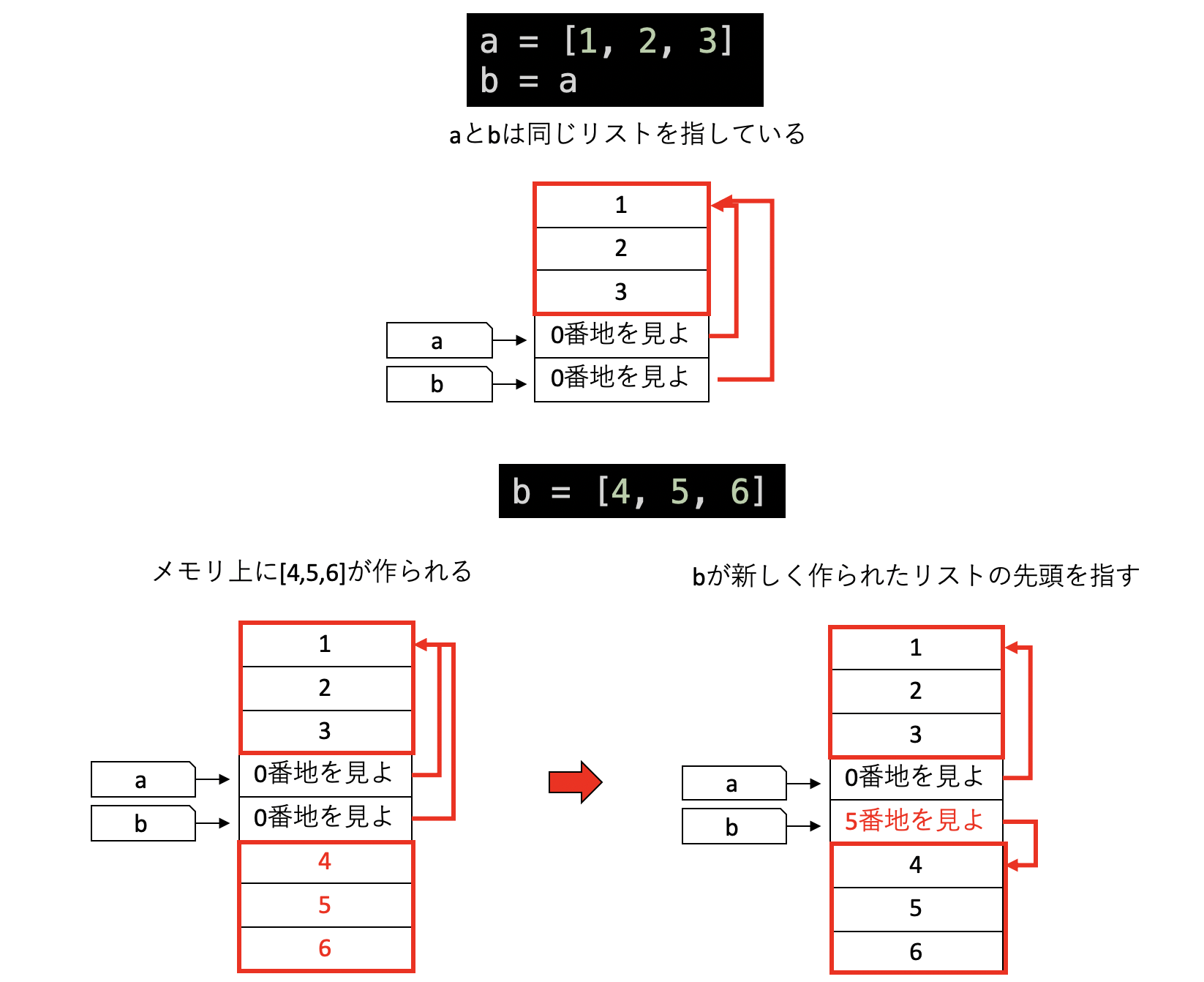
さて、同じリストを指している変数a、bがある時、bに異なるリストを代入する。
a = [1, 2, 3]
b = a
b = [4, 5, 6]以後、aとbは異なるリストを指すようになるため、bを修正してもaは影響を受けなくなる。
これはb = aを実行した時点ではaとbは同じリストを指しているが、b = [4, 5, 6]を実行すると、まずメモリ上に[4, 5, 6]を表現するデータが作られ、その後bの指す内容が新しく作られたリストの先頭の場所となるため、aとbが無関係となるためである。
リストを指す変数は、リストそのものではなく、リストの先頭の場所を記録した情報を指している。このように、値そのものではなく、「この場所を見よ」というような情報を 参照(reference) と呼ぶ。
参照の値渡し
前回「関数」を学び、今回「リスト」を学んだ。これにより、関数の引数としてリストを受け渡せるようになった。この時、注意すべきことがある。まず、関数の引数は、関数が作るブロック内だけで有効なローカル変数である。グローバル変数と同じ名前をつけても、別の変数として扱われる。
こんなコードを見てみよう。
def func(a):
a = 2
a = 1
func(a)
print(a) # => 1関数funcは、引数として変数aを受け取る。この時、aの値がコピーされ、「関数内のローカル変数a」が作成される。この変数aは関数内だけで有効なので、関数内で値を変更しても、外部の変数であるaに影響は与えない。このような情報の渡し方を
値渡し (call by value) と呼ぶ。
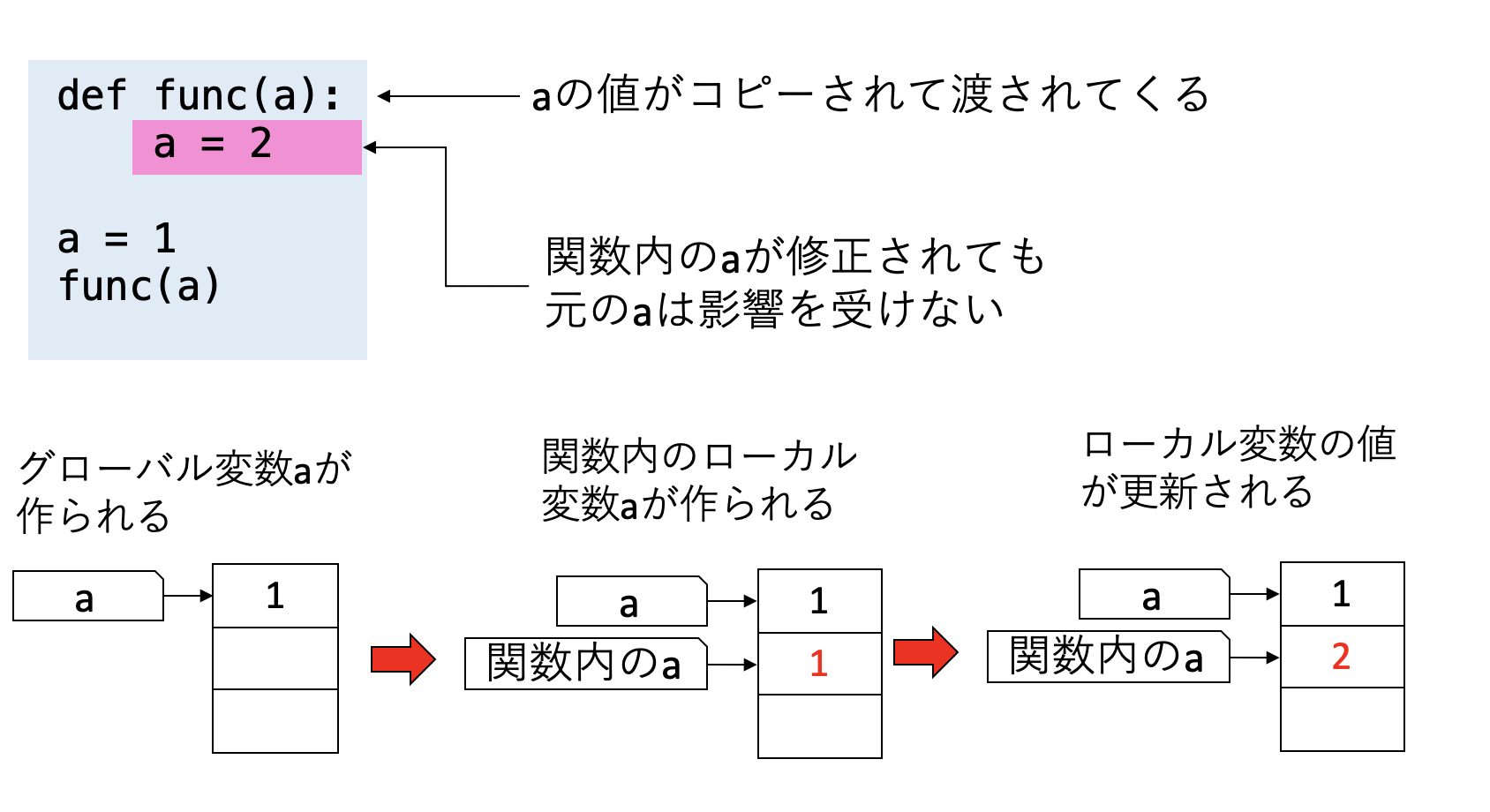
このように、関数の引数としてグローバル変数と同じ名前を使ったり、関数内でグローバル変数と同じ名前のローカル変数を宣言しても、グローバル変数とは別の変数として扱われる(バグの原因となるので推奨されない)。また「関数の引数は値がコピーされてから渡される」ことは覚えておいて欲しい。
次に、関数の引数としてリストを渡してみよう。リストを表す変数は、リストの「先頭」を指していることは既に説明した。それ以外は先程と同じで、関数の引数は、値がコピーされて渡される。
def func(a):
a[1] = 4
a = [1,2,3]
func(a)
print(a) # => [1,4,3]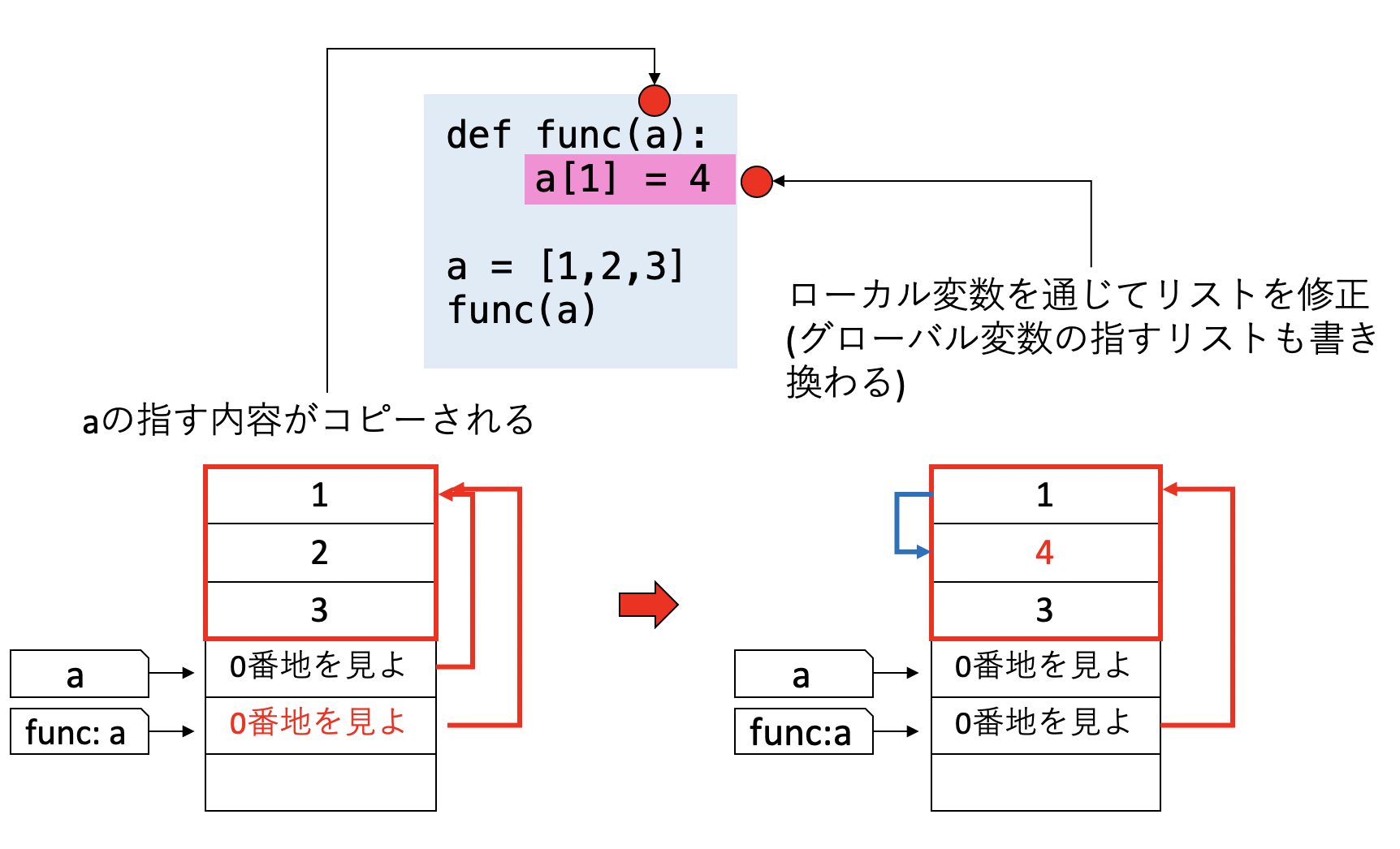
先程説明した、リストのコピーをした時とまったく同じことが起きて、関数内でリストを修正すると、関数の外部でもリストが修正される。
また、引数として受け取ったリストに、あらたにリストを代入すると、それは関数ローカルだけで有効になり、外部のリストに影響を与えなくなるのも理解できるであろう。
def func(b):
b = [4,5,6] # bにあらたなリストを代入
a = [1,2,3]
func(a)
print(a) # => [1,2,3] aは影響を受けない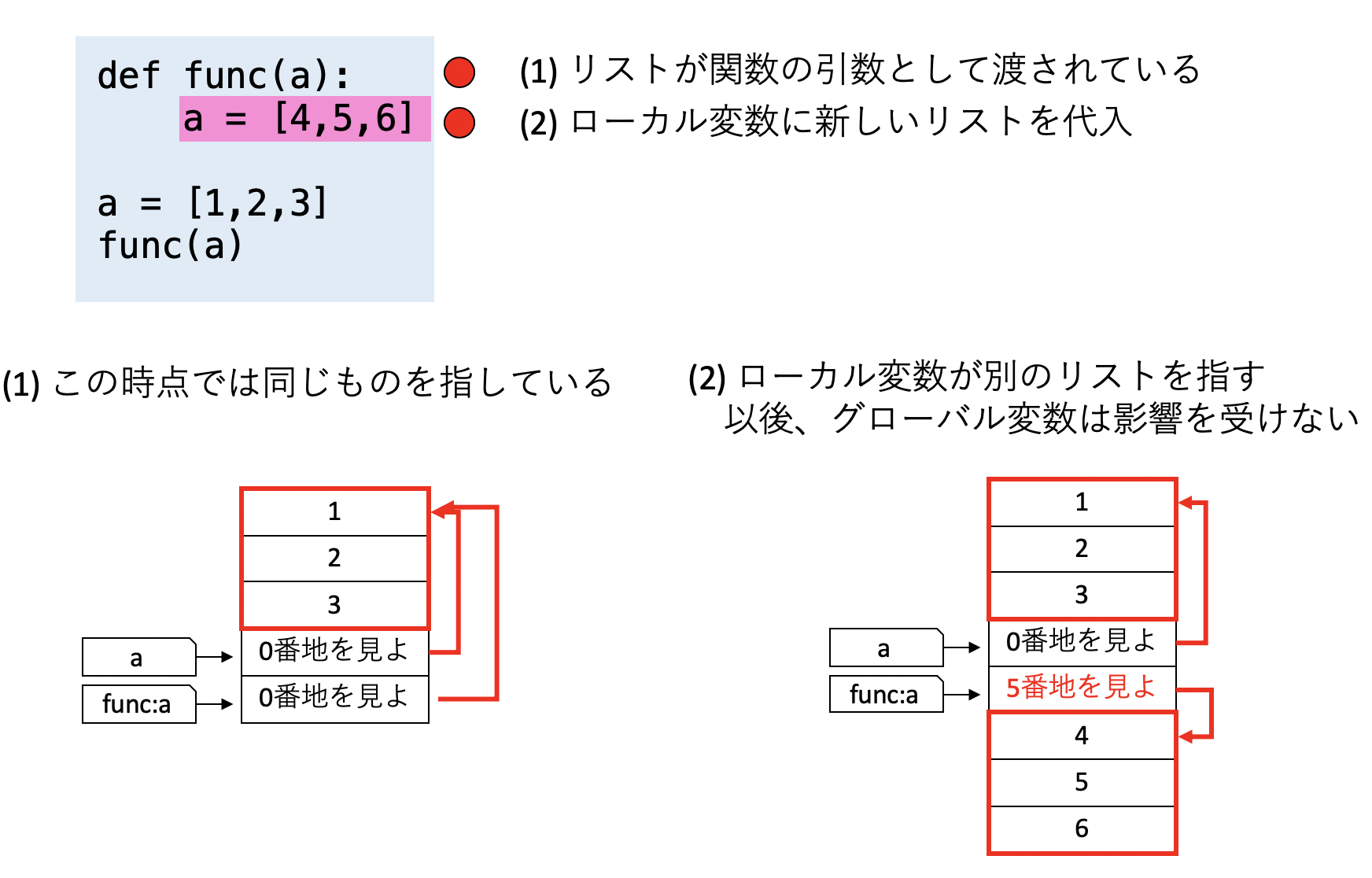
このように、関数の引数に値をコピーして渡す方法を値渡し(call by value)と呼ぶ。Pythonは関数には値がコピーして渡されるため、値渡しとなる。また、リストを指す変数は、リストの値そのものではなく、リストの先頭の場所を指している。このような値の持ち方を 参照(reference)と呼ぶ。
リストを指す変数を関数に渡す時、「リストの先頭の場所」という「参照」の「値」をコピーして渡すので、参照の値渡し (call by sharing)と呼ばれる。いずれにせよ、やっていることは変数の値をコピーして渡しているだけであるが、その変数が参照であるかどうかによって挙動が異なるように見える。この仕組みを完全に理解する必要はないが、将来この問題に直面した時に「参照の値渡し」という言葉や仕組みをしらないと問題解決が難しくなるため、ここではぼんやりと「そういう問題もある」と覚えておいて欲しい。
リスト内包表記
日常業務において、何かまとまったデータを受け取り、それに何か処理をして、まとまったデータとして返す、という処理は非常に多い。例えば講義でレポートを出したら、全員分のレポートを受け取り、それを採点して、それぞれに成績をつける、という処理をしなければならない。同様に、プログラムでも、何かリストを受け取り、そのリストに何か処理をして、新しいリストを作成する、という処理をすることが多い。
簡単な例として、整数のリストを受け取って、要素をすべて二倍にしたリストを作成するようなコードを書こう。普通にループを回すとこんな感じに書けるであろう。
source = [0,1,2]
result = []
for i in source:
result.append(i*2)Pythonにはリスト内包表記 (list comprehension)という表記法があり、上記のコードは以下のように書ける。
source = [0,1,2]
result = [2*i for i in source]リスト内包表記は
[新しいリストの要素 for 元のリストの要素 in 元のリスト]という書き方をする。リスト内包表記は「後ろから」読むのがコツである。
つまり、
[2*i for i in source]という内包表記は、
sourceというリストに含まれる- それぞれの要素
iについて 2*iを要素とするような新しいリストを作ってください
という意味となる。

もちろんsourceのところに直接リストを入れてしまって、
result = [2*i for i in [0,1,2]]としてもかまわない。また、rangeを使って
result = [2*i for i in range(3)]と書くこともできる。リスト内包表記は「Pythonらしい」書き方で、使い方によってはスマートに書けるが、使いすぎると可読性を損なうこともあるため、バランスよく使って欲しい。
コッホ曲線
リストやタプルについて学んだので、それを利用して「コッホ曲線」を描画してみよう。コッホ曲線とはこんな図形である。
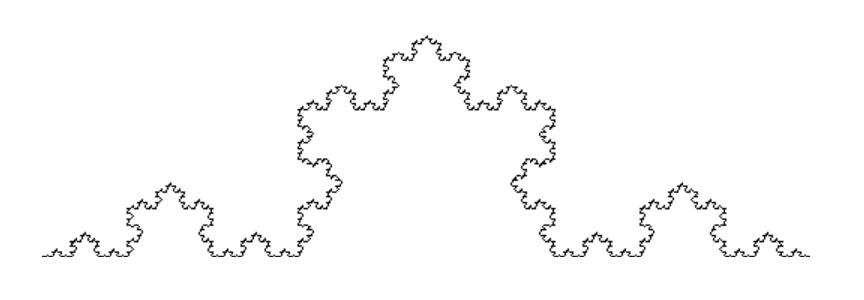
名前を知らなくても、その形は見たことがあるかと思う。この曲線は、以下のような手続きで作成される。
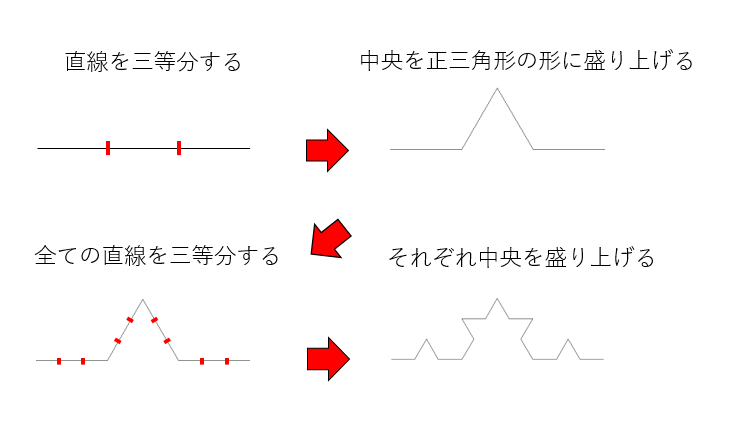
- まず線分を用意する
- 線分を三等分する
- 中央の線分を、正三角形の形に盛り上げる
この手続きをすると、一本の線分が4本の線分に変換される。こうしてできた4本の線分のそれぞれに同様な手続きを繰り返すと、コッホ曲線ができあがる。
コッホ曲線は、再帰を使って描画するのが自然だが、今回はリストとタプルを駆使してコッホ曲線を描くプログラムを組んでみよう。
コッホ曲線は、すべてつながった線分から構成されている。したがって、ある点から、次の点へのベクトルの集合とみなすことができる。さて、あるベクトルが与えられたとき、それをどのように変換したいかを表現したベクトルのリストを与えて変換することを考える。
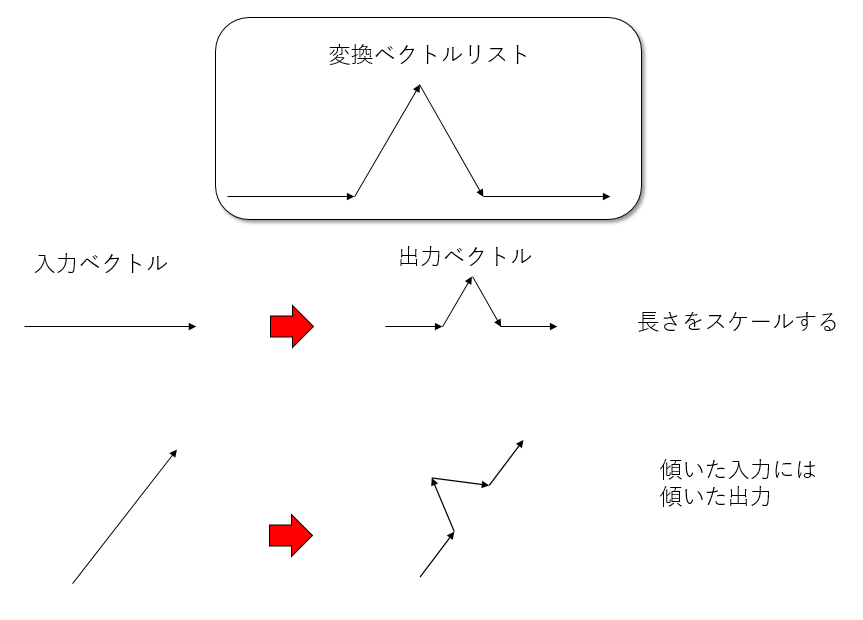
コッホ曲線では、最初にx方向に伸びた長さ1の線分がある。これを2次元ベクトル\((1,0)\)で表現する。これを入力したら\((1/3, 0), (1/6, \sqrt{3}/6), (1/6, -\sqrt{3}/6), (1/3,0)\)の4つのベクトルに変換したい。ここで、最初に与えたベクトルと、変換で与えたベクトルの始点から終点の長さが等しいことに注意せよ。ただ、変換リストを、長さを考えながら与えるのは面倒だ。変換リストとして\((1, 0), (1/2, \sqrt{3}/2), (1/2, -\sqrt{3}/2), (1,0)\)を与えたら、長さを自動調節するようにしよう。 また、傾いたベクトルを入力したら、傾いた4つのベクトルにする。
このような変換プログラムを書いたら、最初にタプルのリスト[(1,0)]を入力すると、それを変換した4つのタプルのリストに変換され、さらにそれを変換したら16個のタプルのリストに変換され……と、この処理を繰り返すことでコッホ曲線を表現するベクトルのリストを作ることができる。以下、そのプログラムを少しずつ作っていこう。
リストとタプル:課題
課題1:コッホ曲線の描画
新しいノートブックを開き、koch.ipynbという名前にせよ。
1. ライブラリのインポート
1つ目のセルでは、必要なライブラリをインポートする。ここではmathライブラリの平方根sqrtと、描画に必要なライブラリをインポートしている。
from math import sqrt
from PIL import Image, ImageDraw2. ベクトルの和の長さ
長さの自動調節のため、変換ベクトルのリストが与えられたら、始点と終点を結ぶベクトルの長さを求めよう。変換ベクトルリストは、タプルのリストとして与える。例えば[(1,0),(0,1)]のようなリストが与えられた時に、\(\sqrt{2} \sim
1.414\)を返すような関数lengthを実装したい。
これは要するにベクトルのリストを受けとって、そのベクトルの和を計算してから、得られたベクトルの長さを返す関数を作ればよい。2つ目のセルに以下を入力せよ。
def length(a):
x, y = 0, 0
for (dx, dy) in a:
x += dx
y += dy
return sqrt(x**2 + y**2)ここでaは、タプルのリスト、例えば[(1,0),(0,1)]のような入力を想定している。for (dx, dy) in a:は、リストaに含まれるタプルを直接(dx, dy)というタプルで受け取るという意味で、冗長に書けば
for ai in a:
dx, dy = aiと同じ意味である。
入力したら、3つ目のセルを使って動作確認をしよう。以下を実行してみよ。
a = [(1, 0), (0, 1)]
length(a)次のような表示がなされれば正しく入力されている。
1.4142135623730951確認が終わったら、3つ目のセルを削除すること。
3. タプルからリストを作成
次に、入力ベクトルを、変換ベクトルリストに基づいて変換することを考えよう。処理は以下の通りである。
- 入力ベクトルの長さと変換ベクトルリストの長さの比
scaleを求める - 入力ベクトルの傾き角度\(\theta\)の\(\sin\)と\(\cos\)の値を求める
- 変換ベクトルリストに含まれるベクトルそれぞれについて、
scale倍して\(\theta\)だけ傾けたものをリストに追加する
以上を実現する以下のコードを、3つ目のセルに入力せよ。
def convert(a, b):
ax, ay = a
alen = sqrt(ax**2+ay**2)
c = ax/alen
s = ay/alen
scale = alen/length(b)
b = [(scale*x, scale*y) for (x, y) in b]
b = [(c * x - s* y, s *x + c * y) for (x, y) in b]
return b上記を実装したら、4つ目のセルで動作確認をしよう。
例えば入力として(0,1)というベクトルを、変換リストとして[(1,1),(1,-1)]というリストを与えたら、[(-0.5, 0.5), (0.5, 0.5)]という出力が得られなくてはならない。
入力
a = (0,1)
b = [(1,1),(1,-1)]
convert(a,b)出力
[(-0.5, 0.5), (0.5, 0.5)]正しい動作が確認できたら、テスト用のセルを削除しておこう。
4. タプルのリストそれぞれに適用
今、「ベクトルをタプルとして与えられたら、変換ベクトルリストに従って、タプルのリストに変換する関数」をconvertとして実装した。これを使えば、「タプルのリスト」が与えられたとき、それぞれのタプルにconvertを適用した結果をまとめたリストを作る関数applyは簡単に実装できる。以下を4つ目のセルに入力せよ。
def apply(a, b):
r = []
for i in a:
r += convert(i, b)
return r入力したら動作確認しよう。5つ目のセルに以下を実行し、結果が正しいことを確認せよ。
入力
a = [(1,0),(0,-1)]
b = [(1,1),(1,-1)]
apply(a,b)出力
[(0.5, 0.5), (0.5, -0.5), (0.5, -0.5), (-0.5, -0.5)]動作確認ができたら、テスト用のコード(5つ目のセル)は削除してよい。
5. 線の描画
ベクトルのリストが与えられたら、描画するのは難しくない。与えられたベクトルの通りに線を描画すればよい。ただし、線を描画したら、次に描画する始点を、現在の終点に取り直す必要がある。
以下のプログラムを、5つ目のセルに入力せよ。
def draw_line(draw, a, size):
x1, y1 = 0, 0
for (dx, dy) in a:
x2 = x1 + dx
y2 = y1 + dy
draw.line((x1, size/2- y1, x2, size/2 - y2), fill=(255, 255, 255))
x1, y1 = x2, y2これは、ベクトルのリストを受け取り、そのベクトルの通りに線を描画する関数である。
6. 画像の表示
では、最後に描画してみよう。以下のコードを6つ目のセルに入力せよ。
size = 512
N = 1
img = Image.new("RGB", (size, size))
draw = ImageDraw.Draw(img)
a = [(size, 0)]
b = [(1, 0), (0.5, sqrt(3.0) / 2), (0.5, -sqrt(3.0) / 2), (1, 0)]
for _ in range(N):
a = apply(a, b)
draw_line(draw, a, size)
imgここまで正しく入力できていれば、上向きの三角形が一つ表示されたはずだ。これはコッホ曲線の一段階目の変換をした画像である。
できていたら、Nの数字を一つずつ増やしてみよ。最大でも5くらいにとどめておくこと。
課題2:オリジナルのフラクタル曲線
6つ目のセルのbのリストに好きなベクトル列を入れて、オリジナルのフラクタル曲線を作成せよ。
例えば、繰り返し数をN=1としてから、
b = [(1,0),(0,1),(1,0),(0,-1),(1,0)]として描画し、繰り返し数を増やした場合にどんな図形になるか想像してみよ。想像した後にN=5に変えて描画し、想像と合致していたか確認せよ。
発展課題:色付きフラクタル曲線
コッホ曲線の線分に色を塗るプログラムを組んでみよう。まずは一色で塗るプログラムを書く。
7. 線に色を塗る
7つ目のセルに、色付きの線を塗る関数draw_line_colorを入力せよ。
def draw_line_color(draw, a, colors, size):
x1, y1 = 0, 0
for i, (dx, dy) in enumerate(a):
x2 = x1 + dx
y2 = y1 + dy
c = colors[0]
draw.line((x1, size/2- y1, x2, size/2 - y2), fill=c)
x1, y1 = x2, y2これは、色のリストcolorsを受け取るが、その最初の要素colors[0]だけを使って色を塗るコードになっている。
8. 色付きのフラクタル図形
8つ目のセルに、draw_line_colorを使った描画プログラムを書いてみよう。
size = 512
N = 1
img = Image.new("RGB", (size, size))
draw = ImageDraw.Draw(img)
a = [(size, 0)]
b = [(1, 0), (0.5, sqrt(3.0)/2), (0.5, -sqrt(3.0)/2), (1, 0)]
c = [(255, 0, 0), (0, 255, 0), (0, 0, 255)]
for _ in range(N):
a = apply(a, b)
draw_line_color(draw, a, c, size)
img成功したら、赤一色になったはずである。ここから、線を一本書くたびに色を変えながら描画するコードに修正せよ。
- ヒント1:
修正するのは
draw_line_color関数である - ヒント2:
リスト
colorsのサイズはlen(colors)で取得できる - ヒント3:
ループカウンタ
iを、リストcolorsのサイズで割った余りを活用せよ - ヒント4:
ある数
iを3で割ったあまりはi % 3で得ることができる
完成したら、オリジナルのフラクタル図形も色付きにしてみよ。
内包表記
リスト内包表記を使うとコードを簡潔に書くことができる。先程書いたconvert関数を見てみよう。
def convert(a, b):
ax, ay = a
alen = sqrt(ax**2+ay**2)
c = ax/alen
s = ay/alen
scale = alen/length(b)
b = [(scale*x, scale*y) for (x, y) in b]
b = [(c * x - s* y, s *x + c * y) for (x, y) in b]
return bbに関してリスト内包表記を使っている部分がある。
b = [(scale*x, scale*y) for (x, y) in b]
b = [(c * x - s* y, s *x + c * y) for (x, y) in b]
return bこれは、
- タプルのリスト
bの要素(x,y)それぞれについて、まず(x,y)をそれぞれscale倍したリストを作成せよ - そうしてできた新しいリスト
bの要素(x,y)それぞれについて、(c * x - s* y, s *x + c * y)という変換(回転行列の演算)をしたリストを作成せよ - できたリストを
bに返せ
という意味だ。毎回bに上書き代入していることに注意。
これを、for文で書くとこのようになるだろう。
r = []
for (bx, by) in b:
bx *= scale
by *= scale
nx = c * bx - s * by
ny = s * bx + c*by
r.append((nx, ny))
return rこれは
rという空リストを作成しておくbの要素を(bx, by)というタプルで受け取るbx, byの要素をそれぞれscale倍するnx = c * bx - s * by、ny = s * bx + c*byという変換(回転行列の演算)をして- 得られた
(nx, ny)というタプルをrに追加し rを返す
という処理をしている。リスト内包表記を使うと、for文が消え、かつ「リストにどのような処理を施しているのか」が明確になったのがわかるであろう。しかし、なんでも内包表記を使いすぎると、逆に何をやっているかの手続きがわかりづらくなる場合もある。リスト内包表記を使った方が良いか、素直にforで回した方が良いかは場合によるので、なんでもかんでも内包表記を使おうとせず、どちらが良いか毎回考えながら決めること。
余談:OSを作ってミュージシャンになった人
普段、Windowsが入っているパソコンを使うことが多いであろう。WindowsとはOS (Operating System)の一種である。OSとは基本ソフトとも言われ、ユーザとハードウェアの仲立ちをする非常に重要なソフトウェアだ。マイクロソフトはMS-DOSというOSの成功から急成長した会社だが、現在はWindows というOSを開発している。さて、Windowsには様々な種類があるが、2006年にリリースされた「Windows Vista」というOSがあった。私はVistaがプリインストールされたノートPCを購入したが、Vistaのあまりのひどさに「これを開発したのは誰だ?」と思って調べてみたら、開発責任者はVistaの発売翌日にマイクロソフトを退職し、ミュージシャンになっていた。彼の名前はジム・オールチン。Windows 95を作るはずの人物であった。
1994年。マイクロソフトのCEO、ビル・ゲイツは「指先で情報を」という基調講演を行った。当時マイクロソフトはWindows 3.1の後継となり、Appleの洗練されたOSに対抗できる次世代OSがぜひとも必要であった。そのために進められていたのが「Cairo」というプロジェクトであり、そのリーダーがジム・オールチンであった。しかし、Cairoの進捗は悪く、別に「Chicago」というプロジェクトが走り出した。最終的にCairoはChicagoに破れ、Chicagoが「Windows 95」としてリリース。Windows 95は大ヒットし、市場におけるマイクロソフトの立場を盤石なものにした。
マイクロソフトはコンシューマ向けであるWindows 95とは別に、サーバ向けに安定動作するWindows NTの開発も進めていた。そのストーリーは「闘うプログラマー」に詳しいので是非読んでみてほしい。コンシューマ向けに使いやすい95ファミリと、サーバ向けに安定しているNT、その両方の良さを受け継いだOSがWindows XPで、これまたヒット、Windowsユーザを一気に増やすことに成功した。
2001年、XPのリリースと同時に、ジム・オールチンをリーダーとしてXPの後継となるOS開発プロジェクトが始まった。コードネームはLonghorn、後のVistaである。Vistaは当初、XPのマイナーバージョンアップという位置付けであったが、いつのまにか野心的な機能が次々と追加され、プロジェクトは膨れ上がっていった。もともと2001年にリリースされたXPの後を継いで2003年頃にリリースされるはずだったが、リリース延期を重ねていく。そして2005年頃にどうにもならなくなり、プログラムの作り直しを決断する(Longhorn Reset)。そこから一年でなんとかVistaはリリースされたが、約束された先進的な機能はほとんど実装されず、VistaプリインストールマシンはWindows XPへダウングレードができるようにされるなど市場からも不評であり、マイクロソフトはOSのリリース計画を大幅に変更せざるを得なくなった。
ジム・オールチンは、Cairoで実現できなかった「指先で情報を」というスローガンをVistaで実現しようとしたのだろうか。Vistaで約束され、実装されなかった機能の多くは、Cairoで実現しようとしていたものと重なるものが多い。ジム・オールチンの公式サイトには「私のマイクロソフトでの最大の貢献はサーバービジネスだ」とあり、その経歴には、キャリアのほぼすべてで関わったはずのCairoとVistaの名前はない。