 A Robot’s Sigh
A Robot’s Sigh
ChainerでMNISTを学習させた結果を使ってブラウザで手描き数字認識
ChainerでMNISTを学習させた結果を使ってブラウザで手描き数字認識
はじめに
機械学習、してますか?
最近流行ってるみたいだからとりあえず機械学習やってみようとして、ChainerのMNISTサンプル動かして、なんかロスが減ってるみたいだから学習できているみたいだなぁ、というところまで来た後、「次はどうすればいいんだろ?」と途方にくれたことはありませんか。僕はくれました。
で、気を取り直して「せっかく手描き文字を学習させたのだから、自分の手描き文字を認識させたい」とか思ったとしますよね。さて、自分の手描き文字をどういう形にして何にどうやって渡せばいいのか、途方にくれたことはありませんか。僕はくれました。
というわけで、ChainerでMNISTの学習をさせたモデルをJavaScriptで取り込んで、ブラウザ上で手描き文字認識をさせるサンプルを書いてみました。ソースコードは以下の場所においておきます。 https://github.com/kaityo256/mnist_check
以下はオンラインで試せるデモです。 https://kaityo256.github.io/mnist_check/ ロードが完了すると「Check」ボタンが押せるようになります。左側に数字を書いて「Check」を押すと、数字を認識します。
(2018年9月19日追記)以下で認識精度が悪いのは、前処理を行っていなかったからでした。前処理付きバージョンの解説を以下に書きましたので、そちらも合わせてご参照ください。 ↓ ブラウザで手描き数字認識 (前処理付き版)
使い方
学習の実行にはChainerが必要ですので、予めインストールしておいてください。学習させた結果を使うだけならChainerは不要です。
学習
まず、モデルを学習させます。リポジトリのtrain.pyを実行するだけで、MNISTデータを取ってくるところからやってくれます。
$ python train.py
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy
1 0.439235 0.185205 0.878933 0.9457
2 0.145111 0.113943 0.957883 0.9669
3 0.0952712 0.0904553 0.972017 0.9721
total [########..........................................] 16.67%
this epoch [################..................................] 33.33%
200 iter, 3 epoch / 20 epochs
19.349 iters/sec. Estimated time to finish: 0:00:51.681640.
実行は数分で終わり、カレントディレクトリにtest.modelが出力されます。これはChainerがモデルをシリアライズしたもので、実体はNumpyのデータをzip圧縮したものです。
$ zipinfo test.model
Archive: test.model
Zip file size: 4597668 bytes, number of entries: 6
-rw------- 2.0 unx 2458704 b- defN 18-Mar-22 17:06 predictor/l2/W.npy
-rw------- 2.0 unx 3216 b- defN 18-Mar-22 17:06 predictor/l1/b.npy
-rw------- 2.0 unx 120 b- defN 18-Mar-22 17:06 predictor/l3/b.npy
-rw------- 2.0 unx 3216 b- defN 18-Mar-22 17:06 predictor/l2/b.npy
-rw------- 2.0 unx 2458704 b- defN 18-Mar-22 17:06 predictor/l1/W.npy
-rw------- 2.0 unx 31440 b- defN 18-Mar-22 17:06 predictor/l3/W.npy
6 files, 4955400 bytes uncompressed, 4596974 bytes compressed: 7.2%
##データの変換
シリアライズデータをJavaScript向けにデータ変換します。というか以前C++向けに変換したものを流用します。
$ python export.py
Exported to test.dat
[ -9.99378014 -11.68352318 -0.12913226 12.59506226 -37.89603806
5.77510595 -6.72662544 -10.10519028 6.5484581 -8.09554958]
test.modelから、test.datが作られました。数字はデバッグ用の出力で、後で使います。test.datは、純粋に単精度実数(float)を順番に並べただけのバイナリデータです。
ブラウザでの動作確認
ブラウザで、check.htmlを開きます。最初はこんな画面になります。

最初はチェックボタンが使えません。「ファイルを選択」で先程つくった test.datを読み込むと有効化されます。
左の黒いキャンバスに何か適当に数字を書いて「Check」ボタンを押してください。Chainerで学習させたモデルが数字を推定してくれます。
以下は「5」を推定したところです。

右は実際にモデルに食わせる28*28の解像度に変換されたイメージです。
簡単な説明
MNISTのデータ構造については、MNISTのデータを仕分けしてPNGファイルで保存を参考にしてください。入力データは28*28の0から1までの浮動小数点データ、ラベルは0から9までの整数値です。
これを適当なモデルで学習させます。今回は入力2828ユニット、中間層も2828ユニット、出力は10ユニットの三層のニューラルネットにしてみました。これを簡単にラップしたmodel.pyを使って学習させた後、データを保存します。詳細はRe:ゼロから始めるChainer生活を参照してください。
学習結果をC++向けにエキスポートします。詳細はChainerで学習したモデルをC++で読み込むを参照してください。リポジトリにあるmodel.jsは、ほぼこれのmodel.hppをそのままJavaScriptに移植したものです(なのですごくC++っぽく書いてある)。
さて、ここまでで、C/C++で言うところのfloat型、JavaScriptで言うところのfloat32型1がずらずらならんだバイナリファイルtest.datができたはずなので、これをブラウザで読み込みます。
ブラウザでJavaScriptを使ってローカルにある単精度浮動小数点数型データ(float32)のバイナリデータを読みこむ方法はJavaScriptでfloat32のバイナリファイルを読み込むに書いたとおりです。
とりあえずmodel.jsではデータを一括で読み込んで、それをスライスして各行列やらバイアスやらに振り分けています。そのためにデータを簡単にラップしたFloat32Streamクラスを作りました。
Float32Stream = function(result){
this.a = new Float32Array(result);
this.index = 0;
}
データをC++のファイルストリームのような気持ちで使うためのクラスです。Linkクラスはコンストラクタで入力の数、出力の数と、このストリームを受け取ります。
Link = function(n_in, n_out, fs) {
this.n_in = n_in;
this.n_out = n_out;
this.W = fs.a.slice(fs.index,fs.index+n_in*n_out);
fs.index += this.W.length;
this.b = fs.a.slice(fs.index,fs.index + n_out);
fs.index += this.b.length;
}
ストリームの現在位置をLinkクラス側で変更しているのがかっこ悪いですが、気にしないことにします。
Modelクラスは、Linkクラスをまとめたものです。
Model = function(fs) {
this.n_in = 28 * 28;
this.n_units = 28 * 28;
this.n_out = 10;
this.l1 = new Link(this.n_in, this.n_units, fs);
this.l2 = new Link(this.n_units, this.n_units, fs);
this.l3 = new Link(this.n_units, this.n_out, fs);
var x = new Float32Array(this.n_in);
x.fill(0.5);
var y = this.predict(x);
console.log(y);
}
ここで、コンソールへのデバッグ用出力があります。これは「入力が全部0.5だった時の出力」です。全く同じものをexport.pyが出力しているため、ここで出力が一致するかどうか調べることで、正しくモデルデータが読み込めたかチェックできます。
canvas要素への描画は難しくないと思います。「チェック」ボタンが押されたら、まずcanvasのデータからモデルに食わせるためのデータを作ります。それがdraw.jsのgetX関数です。
function getX(canvas){
var h = canvas.height;
var w = canvas.width;
img = canvas.getContext('2d').getImageData(0,0,h,w);
var x = new Float32Array(28*28);
data = img.data
for(var i=0;i<28;i++){
for(var j=0;j<28;j++){
var sum = 0;
for(var k=0;k<16;k++){
for(var l=0;l<16;l++){
sx = i*16+k;
sy = j*16+l;
var s = sx+sy*16*28;
if (data[s*4]>128){
sum++;
}
}
}
x[i+j*28] = sum/256.0;
}
}
return x;
}
キャンバスの大きさは一辺448ピクセルですが、これは28×16です。従って、16×16ピクセルのデータを一つにピクセルにまとめることで、全体として28×28ピクセルに縮小されます。16×16ピクセルのうち、どれだけ白マスがあるかを数えて、その割合をFloat32Arrayに突っ込んでいき、それを返します。
こうして作った入力xを、Model.recognize(x)として食わせばどの数字であるかを推定してくれます。実際にはまずModel.predict(x)で出力ベクトルを得てから、そのうち重み最大のインデックスを返しています。
まとめ
ChainerでMNISTを学習させたモデルを適当にコンバートし、JavaScriptで読み込んでブラウザ上で手描き数字認識をしてみました。やってみるとわかりますが、意外に面倒くさかったです。機械学習は「ちょっとやってみる」サンプルはいくらでも転がっていますが、少しでも踏み込んだことをしようとすると途端に面倒くさくなりますね。まぁ、どの分野もそういうものなのかもしれませんが・・・
おまけ
実際に認識させてみるとわかりますが、意外に認識してくれません。学習のさせかたが悪いのかもしれませんが・・・
まず、「4」の認識に苦労しています。

学習に使ったデータはほとんど「4」の上を開けていた形になっています。例えばこんな感じです。
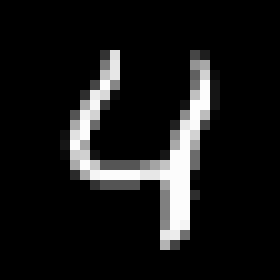
なので、そういう字を書くと認識されやすくなります。

あと、意外に苦戦するのが「1」です。特に真ん中からずれると誤認識が増えますね。

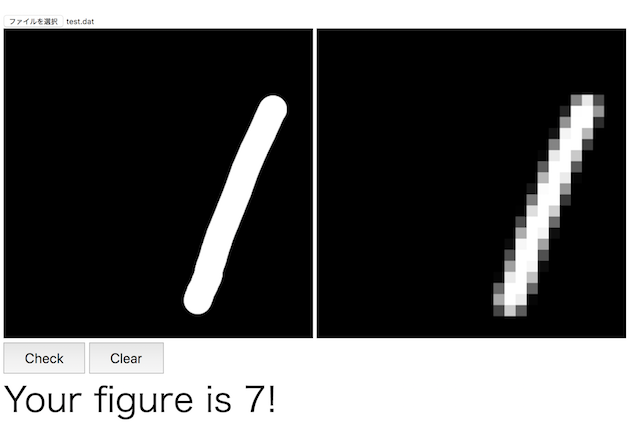
左にずれると「4」だと思って、右にずれると「7」だと思うの、なんとなくわかる気がしません?
こうやって遊んでみると「機械学習」が何を学習して何を認識しているつもりのか、なんとなくわかってきて面白いですね。
参考文献
- Chainer v3 ビギナー向けチュートリアル Chainer初心者はまずこれを読むと良いかも。
- MNISTのデータを仕分けしてPNGファイルで保存
- Re:ゼロから始めるChainer生活
- Chainerで学習したモデルをC++で読み込む
- JavaScriptでfloat32のバイナリファイルを読み込む
-
実際にそういう呼び方をするのかは知りません。 ↩