 A Robot’s Sigh
A Robot’s Sigh
Re: PowerPoint for Macが吐くPDFが重いんです
Re: PowerPoint for Macが吐くPDFが重いんです
PowerPoint for Macが吐くPDFが重いんですの続きです。
TL;DR
- PowerPoint for Macの吐くPDFのサイズが大きいのは、
- 画像を大きなサイズで保存し
- かつ同じファイルであっても複製して保存し
- かつ可逆圧縮をしているから
- (2018年8月22日追記)ただし「環境設定→一般→印刷品質(用紙/PDF)」で「目的の品質」を「低」とすると、かなりマシなサイズになる。
- WindowsのPowerPointが吐くPDFのサイズが小さいのは
- 画像を元ファイルのサイズで保存し
- かつ同じファイルは複製せず
- かつ不可逆圧縮をしているから
はじめに
「PowerPoint for Macが吐くPDFが重いんです」で、PowerPoint for Macが吐くPDFのサイズがやたら大きく、同じファイルWindowsのPowerPointでエクスポートしたら相当小さいPDFが出力されることを書いた。
前の記事では同じ画像ファイルを含むスライドを複数枚コピーしたものなので、
- Macは同じ画像ファイルなのに別々に保存している
- そもそもPDFに埋め込む画像ファイルのサイズが大きい
ということが予想される。というわけでそれを調べて見よう。
PDFの中身
PDFの構造は参考文献を参照してもらうことにするが、中身はこんな形になっている。
%PDF-1.5
番号 0 obj
オブジェクトの中身
endobj
番号 0 obj
オブジェクトの中身
endobj
trailer (トレーラー)
xref (相互参照テーブル)
startxref (相互参照テーブルの位置)
アドレス
%%EOF
PDFのフォーマットをざっくり言うと
- 「%PDFバージョン」で始まり、「%EOF」で終わる
- 最後の方に目次情報がある
- 後はオブジェクトの羅列である
オブジェクトには通し番号が付いており、例えば
21 0 obj
1573280
endobj
というオブジェクトは、
- 通し番号は21番で、
- 世代番号は0で、
- 中身として1573280という数字
を持つ。世代番号についてはとりあえず0だと思っておけば良い。
また、オブジェクトは別のオブジェクトを参照することができる。例えば今のオブジェクトは21 0 Rとすると、その中身である1573280を指定したことになる。
オブジェクトは、バイナリデータを含む場合がある。バイナリデータはstream、endstreamで挟まれており、その直前にバイナリデータの長さが指定されている。ここまでわかればPDFの構造解析ができる。
PDF構造ダンプスクリプト
どんなPDFを吐いたか調べるのに、とりあえずバイナリデータのみスキップして出力するスクリプトを書いてみよう。
buf = File.binread(ARGV[0])
pos = 0
head = 0
in_stream = false
while pos < buf.size
if buf[pos] == "\n"
s = buf[head..pos]
if in_stream
in_stream = false if s =~ /endstream/
else
if s =~ /stream/
in_stream = true
else
puts s if s.ascii_only?
end
end
head = pos + 1
end
pos = pos + 1
end
要するにstreamとendstreamで挟まれたもの以外を出力しているだけのスクリプトである。一度バイナリとして一括で読み込んでいるのは文字コードの問題を扱うのが面倒だったため。
また、PDFは確実にバイナリファイルであることがわかるように、二行目のコメントに非ASCII文字を置くことが推奨されている。それを飛ばすためにs.ascii_only?でチェックしている。
これで、Win、Macそれぞれで作ったPDFファイルを保存してみよう。
$ ruby win.pdf > win.txt
$ ruby mac.pdf > mac.txt
結果
PowerPoint for Macが吐いたPDF
まず、mac.txtから画像っぽいものを探す。
9 0 obj
<< /Length 10 0 R /Type /XObject /Subtype /Image /Width 1368 /Height 1668
/Interpolate true /ColorSpace 8 0 R /SMask 11 0 R /BitsPerComponent 8 /Filter
/FlateDecode >>
endobj
10 0 obj
1573280
endobj
11 0 obj
<< /Length 12 0 R /Type /XObject /Subtype /Image /Width 1368 /Height 1668
/ColorSpace /DeviceGray /Interpolate true /BitsPerComponent 8 /Filter /FlateDecode
>>
endobj
12 0 obj
60287
endobj
まず、最初の9番のオブジェクトを見てみる。
/Length 10 0 R長さは10 0 R、つまり10番のオブジェクトを指している。10番のオブジェクトは直後にあって、中身は1573280であるから、長さは1573280バイトである。/Type /XObject /Subtype /Imageこれが画像データであることを示している/Width 1368 /Height 1668サイズは1368x1668であることを示す/SMask 11 0 Rこれは透明効果のためのマスク用データが11番のオブジェクトであることを示す。/ColorSpace 8 0 R色は8番のオブジェクトを見よ、とある。8番のオブジェクトを見ると[ /ICCBased 13 0 R ]つまり、ICCBasedカラー空間を使っている/Filter /FlateDecode圧縮方法としてFlateDecodeを指定している
ここで重要なのは、圧縮方法としてFlateDecode、すなわちzipなどに使われる可逆圧縮が指定されていることである。さらに圧縮後のサイズも1573280バイトとかなり大きい。
直後に9番の画像の透明効果のためのマスクデータとして11番のオブジェクトがあり、実体はグレースケールの画像である。こちらも同じサイズ、同じ圧縮方法だが、圧縮後のサイズは60287バイトとなる。
PDFファイルの中身を見ると、この画像が5個出てくる。すなわち、同じ画像ファイルが5個複製されて保存されている。また圧縮方法が可逆であり、サイズも大きい。
このPDFのファイルサイズは8177073バイトであり、画像ファイルだけで(1573280+60287)*5 = 8167835バイトある。つまり、このPDFファイルは99.9%がこの画像ファイルで占められている。
また、元画像の大きさは 656x800であるにも関わらず、なぜかそれより大きな1368x1668で保存されていることも謎。
Windows版のPowerPointが吐いたPDF
同様に画像と思しきデータを探すと、こんなのが見つかる。
6 0 obj
<</Type/XObject/Subtype/Image/Width 656/Height 800/ColorSpace/DeviceRGB/BitsPerComponent 8/Filter/DCTDecode/Interpolate true/SMask 7 0 R/Length 39633>>
endobj
7 0 obj
<</Type/XObject/Subtype/Image/Width 656/Height 800/ColorSpace/DeviceGray/Matte[ 0 0 0] /BitsPerComponent 8/Interpolate false/Filter/FlateDecode/Length 12101>>
endobj
6番のオブジェクトがカラー画像、7番のオブジェクトがグレースケール画像を保存している。ここで重要なのは圧縮方法(/Filter)としてDCTDecodeが指定されている点である。DCT=Discrete Cosine Transform、つまり離散コサイン変換であり、これはJPEGなどに利用される不可逆圧縮である。画像サイズは元画像と同じ656x800であり、圧縮後のサイズもカラー39633バイト、グレースケール12101バイトとかなり小さい。さらに、PDF中に画像データはこれだけである。つまり画像の複製も行われていない。
まとめ
MacのPDFのファイルサイズが大きいのは、予想通り「同じ画像データを複製して、かつ大きなサイズで保存しているから」であった。サイズが大きくなるのは「元画像ファイルよりも大きなサイズの画像を」「可逆圧縮で」保存しているのが原因。なぜ元画像ファイルより大きなサイズで保存しているのかは謎。
余談
どうでもいいが、PowerPoint for Macの吐くPDFはやたらと参照が多く、かつ変なところで改行を入れてくる。どうもテキスト部分が85桁を超えると改行している雰囲気がある。どうせstreamがあるからテキストエディタでは開かないのに謎。
参照については、例えば画像のファイルサイズを参照にして後置しているところ見るに、PDFの生成をワンパスでやっている雰囲気がある。
例えば画像データがある時、streamにいれるべき圧縮データを生成する前には圧縮後のサイズがわからない。
先程の例なら
9 0 obj
<< /Length 10 0 R /Type /XObject /Subtype /Image /Width 1368 /Height 1668
/Interpolate true /ColorSpace 8 0 R /SMask 11 0 R /BitsPerComponent 8 /Filter
/FlateDecode >>
endobj
10 0 obj
1573280
endobj
と、画像は9番のオブジェクトとして保存されているが、そのサイズは10番のオブジェクトを参照している。これは、まず画像を保存する際に
9 0 obj
<< /Length 10 0 R /Type /XObject /Subtype /Image /Width 1368 /Height 1668
/Interpolate true /ColorSpace 8 0 R /SMask 11 0 R /BitsPerComponent 8 /Filter
/FlateDecode >>
stream
まで作ってしまってから圧縮データを吐いて、endstreamを出力した後にはもうサイズがわかるので、サイズを10番のオブジェクトとして
10 0 obj
1573280
endobj
と出力する、みたいなことをしているっぽい。Win版はいきなりサイズを保存しているので、(少なくとも画像データの出力に関しては)ツーパスでやっているっぽい。
追記(2018年8月22日)
この記事に対する編集リクエストとして、
「環境設定>一般>印刷品質(用紙/PDF)」において 「低」を選択すると解決する
と教えていただいたので調べてみた。
PowerPoint for Macの環境設定→一般→印刷品質の「目的の品質」を「低」にする。
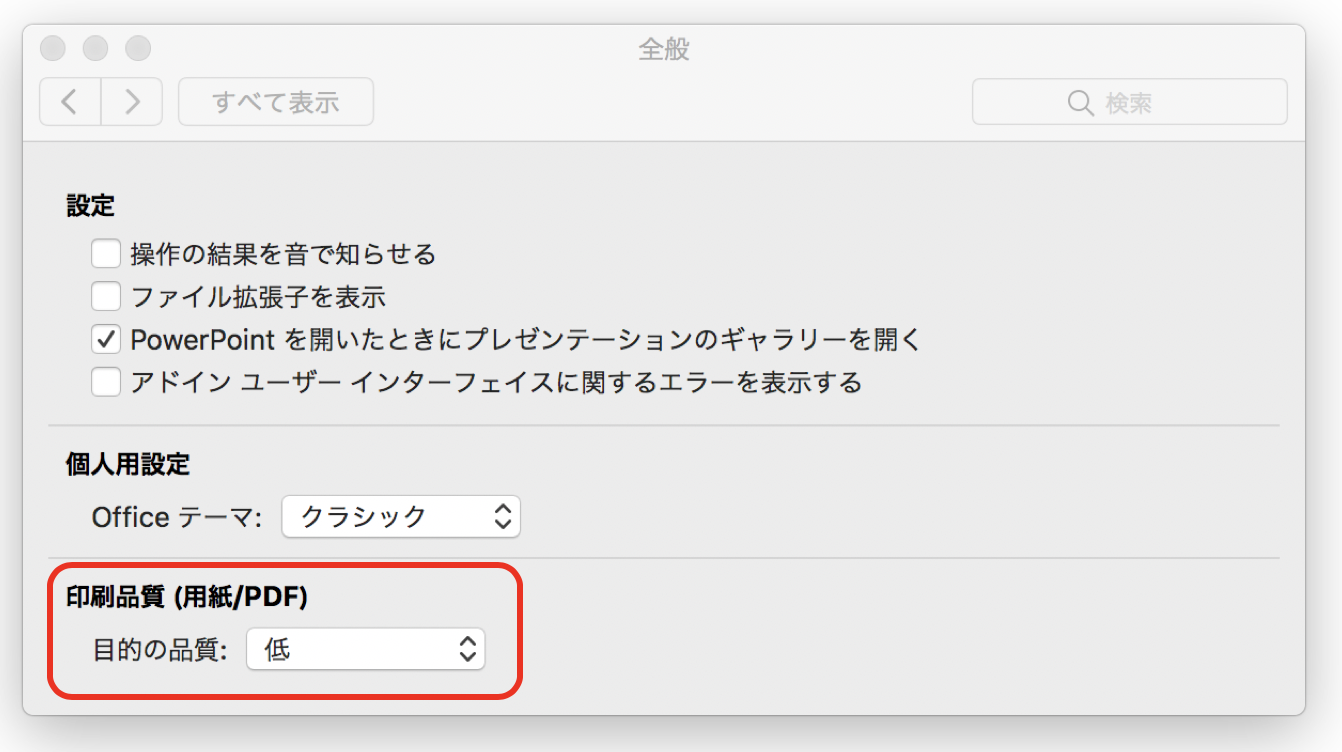
この状態でPDFを出力すると、573KBまでサイズが減る。
392K test.pptx # もとのPPTXファイル
7.8M test.pdf # そのままPDFにエキスポート
560K test2.pdf # 品質「低」でエキスポート
依然としてWindows版でエキスポートした時のファイル(56KB)の10倍以上のサイズだが、これくらいなら許容範囲であろう。
PDFの中身を見てみる。該当部分はこのあたり。
<< /Length 10 0 R /Type /XObject /Subtype /Image /Width 328 /Height 400 /Interpolate
true /ColorSpace 8 0 R /SMask 11 0 R /BitsPerComponent 8 /Filter /FlateDecode
>>
endobj
10 0 obj
107000
endobj
まず、画像のファイルサイズがこれまでひとつ1.5MBとかあったのが、100KBちょいまで下がっている。元画像の大きさは656x800だったのに対し、品質を「高」にすると1368x1668で保存していたのに対し、328x400とちょうど半分の大きさで保存されている。これが5つあるので、ファイルサイズは全体で500KB程度になったと考えられる。
ただし、画像圧縮方法を表す/Filterは/FlateDecode、つまりzipを使った可逆圧縮をしており、かつ全く同じファイルを5つ、コピーして保存している。画像の圧縮を可逆にするか、不可逆にするかはポリシーの問題だが、全く同じファイルを複数回参照する場合に、コピーしてしまう(Mac)か、一つだけ入れて後は参照とする(Win)かは、ポリシーというよりは技術力(というかやる気?)の問題な気がする。
また、「印刷品質」を「高」にすると、「元画像」よりも大きなサイズで保存するのは単純に頭が悪い気がする。