 A Robot’s Sigh
A Robot’s Sigh
ナンプレの正規化 ステップ・バイ・ステップ その3
ナンプレの正規化 ステップ・バイ・ステップ その3
はじめに
Step2では、「一番上にくる行のヒント数の組み合わせ」に着目して枝刈りをおこなった。こいつのC++版を作ろう。といってもほとんどRubyの配列版をそのままC++にするだけなので、内容がほとんど被り、別記事化する必要もないのだが、なんとなくGithubのリポジトリでステップを分けちゃったので記事も分ける。
今回のソースコードはここ。
https://github.com/kaityo256/minlex/tree/master/step3
方針
基本的にはStep2に記載された通り。ただし、Ruby版を組んだ後で、ヘッドボックスのインデックスを返す関数を、ソートあり版、ソート無し版の両方を組む必要がないことに気がついたので、それはまとめることにする。
実装
ヘッドボックスインデックス
ヘッドボックスインデックスとは、「与えられたナンプレの、ヘッドボックス(上位3行)について、もっとも辞書順が小さくなるように並べた時に、どのようなヒントパターンになるか」を表すインデックスとなる。このインデックスでは、ヒントの数字については区別しない。
このインデックスを使って、ボックス行及びボックス列の入れ替えの枝刈りを行う。
実装はこんな感じになるだろう。
int headbox_index(bool sort) {
int min = 16 * 3 + 4 * 3 + 3;
for (int k = 0; k < 3; k++) {
std::vector<int> a(3, 0);
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
if (data[j + i * 3 + k * 9] != 0) a[i]++;
}
}
if (sort) {
std::sort(a.begin(), a.end());
}
int index = 0;
for (int i = 0; i < 3; i++) {
int t = ((1 << a[i]) - 1) << (2 - i) * 3;
index += t;
}
if (index < min) {
min = index;
}
}
return min;
}
Ruby版での反省をもとに、ソートの有無を引数で指定している。
こんなデータを食わせることを考える。
207005000000340000150000009005000001040000320000016500000002084700000010010580000
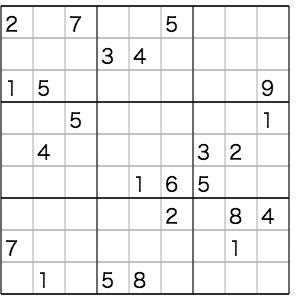
を与えたに、上位3行に注目する。これらのヒント数は上から
(2,1,0)
(0,2,0)
(2,0,1)
なので、まずそういう配列を作る(std::vector<int> a)。この後、ボックス列の入れ替えにより、もっとも辞書順が小さくなるパターンを探すためにソートする。
(0,1,2)
(0,0,2)
(0,1,2)
さて、Ruby版では単純に配列のminを返していたが、さすがにいちいちstd::vectorを返すには遅そうなので、返す値は数字にしよう。3つ組の数字で、それぞれ0から最大3なので、3桁の四進数だと思えばよい。というわけで返り値はintとする。
ボックス列の入れ替えでは、ソートしないインデックスを返せば良い。それが先程しらべた「ソート有り」の場合のインデックスと一致しているもののみ調べる。
ヘッドラインインデックス
ボックス行の入れ替え、及びボックス列の入れ替えが終わったら、次は一番上のボックス行の中の行の入れ替えを行う。そのために、「一番上の行のインデックス(ヘッドラインインデックス)」を返す関数を作る。
これについては、「n行目のインデックスを返す関数line_index」を作って、それを3回呼ぶ関数としてheadbox_indexを作るかちょっと迷ったんだけど、書き方間違えると遅くなりそうだったので別関数にしてみた。書くほどでもないけどこんな感じ。
int headline_index(void) {
std::vector<int> a(3, 0);
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
if (data[j + i * 3] != 0) a[i]++;
}
}
std::sort(a.begin(), a.end());
int index = 0;
for (int i = 0; i < 3; i++) {
int t = ((1 << a[i]) - 1) << (2 - i) * 3;
index += t;
}
return index;
}
ヘッドラインインデックスについてはソートするバージョンしかいらないので引数は不要。
結果
以上の枝刈りを追加して、同じ5000問の正規化をさせてみる。
今回の枝刈り前:
$ time ./a.out sample.txt > sample.minlex
./a.out sample.txt > sample.minlex 136.91s user 0.42s system 98% cpu 2:19.22 total
枝刈り後:
$ time ./a.out sample.txt > test.txt
./a.out sample.txt > test.txt 7.37s user 0.03s system 98% cpu 7.493 total
$ diff sample.minlex ../step1/sample.minlex
というわけで18倍ちょっと高速化された。結果も変わってないので、「切っちゃいけない枝」は切ってないみたい1。
まとめ
Ruby版で実装した枝刈りをC++版に実装してみたら、Ruby版での速度向上が10倍程度だったのがC++版は18倍になった。ただし正規化にかかる時間は問題依存性が大きく、Ruby版は一つの問題の正規化にかかる時間で、C++版は5000問にかかった時間なので、おそらく速度向上は同じくらいなんだと思う。
しかし、5000問の正規化に7秒ということは、一問あたり1.4 msとか? まだちょっと遅い気がするので、もう少しだけ高速化してみる。
その4へ続く。
-
実はここに至るまでに何度か枝を切りすぎて失敗している。「素晴らしい高速化思いついた!」って思って実装してみると、たしかに速度は素晴らしいんだけど、実は想定してなかったパターンがあって、それで切っちゃいけない枝切っちゃってることがわかったりするんだよなぁ・・・ ↩