 A Robot’s Sigh
A Robot’s Sigh
重み付きランダムサンプリングアルゴリズム
重み付きランダムサンプリングアルゴリズム
重み付きランダムサンプリングアルゴリズム
はじめに
あらかじめ指定された重みに従って離散的な値を確率的に選択したい、ということがよくある。例えば[1,4,5]という配列が与えられたら、確率10%で0、40%で1、50%で2というインデックスを返すようにランダムサンプリングしたい。一番手軽な累積和の方法では、テーブル構築に$O(N)$、サンプリングに$O(\log(N))$の計算量となり、多くの場合これで用は足りる。さらに、テーブル構築は$O(N)$だが、サンプリングが$O(1)$となるWalker’s Alias法という強力アルゴリズムもある。
累積和の方法は組むのが簡単で探索が$O(\log(N))$と十分早いし、Walker’s Alias法は探索が$O(1)$と強烈なので、「重み付きランダムサンプリングアルゴリズムは、もうこの2つのどちらかで十分じゃん?」という気持ちになるが、この2つのアルゴリズムでは、重みの部分書き換えができない、という弱点がある。つまり、どこか一つの配列の重みが変更された場合、テーブル構築にまた$O(N)$の手間がかかってしまう。
そこで本稿では二分木を用いたサンプリングアルゴリズムを紹介したい。これはテーブル構築に$O(N)$、探索が$O(\log(N))$だが、一度テーブルが構築されると、一つの重みを変更してもテーブルの更新が$O(\log(N))$でできる。
とりあえず本稿では、
- 累積和
- Walker’s Alias
- 二分木探索
の3つの方法を紹介してみたい。ソースは
https://github.com/kaityo256/randomsampling
においてある。
累積和の方法
まず、最も単純な累積和の方法を組んでみよう。以下、入力する重みの配列として[1,2,3,4,5]を考える。ここから1/15の確率でインデックス0を、2/15の確率でインデックス1を返す関数を作るのが重み付きサンプリングの目的である。
累積和の方法の原理は単純で、重みに比例した長さのバーを積み重ね、そこにダーツを投げれば、面積(つまり重み)に比例した確率で対応するインデックスに当たるでしょう、という思想である。
実装としては、まず事前準備として以下の図のように累積和を作っておく。これは$O(N)$の手間で構築できる。
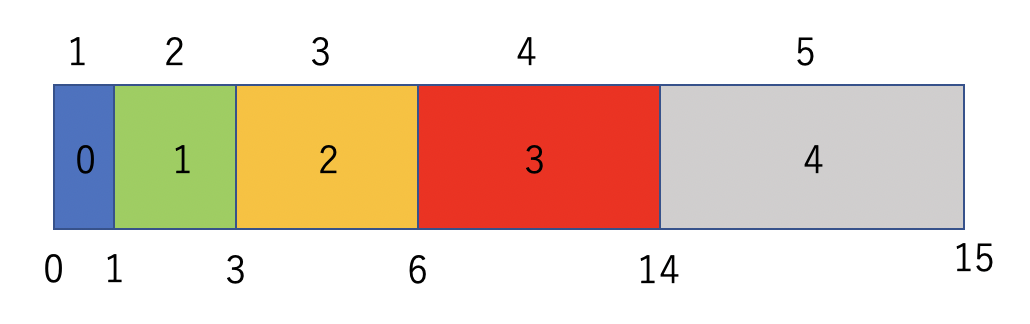
そして、重みの総和(今回は15)に対する一様乱数を振る。例えば10.0という数字が得られたとしよう。これは、6と14の間なので、インデックスとしては3を返せば良い。この「得られた乱数がどことどこの間に挟まっているか」を二分探索で調べるので$O(\log(N))$の手間がかかる。
コンストラクタで重み配列を受け取り、selectでインデックスを返すようなクラスはこんな感じに実装できるだろう。
struct cumulative_sum {
std::vector<double> c_sum;
std::uniform_real_distribution<double> ud;
const std::string name() {
return "Cumulative Sum";
}
cumulative_sum(std::vector<double> &list) {
double sum = 0.0;
for (auto v : list) {
c_sum.push_back(sum);
sum += v;
}
ud.param(std::uniform_real_distribution<double>::param_type(0, sum));
}
int search(double v) {
int imin = 0;
int imax = c_sum.size();
int index = (imin + imax) / 2;
while (imax != index && imin != index) {
if (c_sum[index] < v) {
imin = index;
} else {
imax = index;
}
index = (imin + imax) / 2;
}
return index;
}
int select(std::mt19937 &mt) {
double v = ud(mt);
return search(v);
}
};
特に難しいことはないと思う。
もし、重み配列の一部が書き換わったら、そのインデックス以降の累積和を全て作り直す必要があるため、この手間は$O(N)$である。
Walker’s Alias法
Walker’s Alias法は、$N$個の要素に対して$N$個の箱を作り、その箱をたかだか2つに分解して色を塗り、それぞれの色の面積の合計が元の重みにすることで、$O(1)$の探索を可能とする方法である。
先程の例なら、以下のような5つの箱を作る。
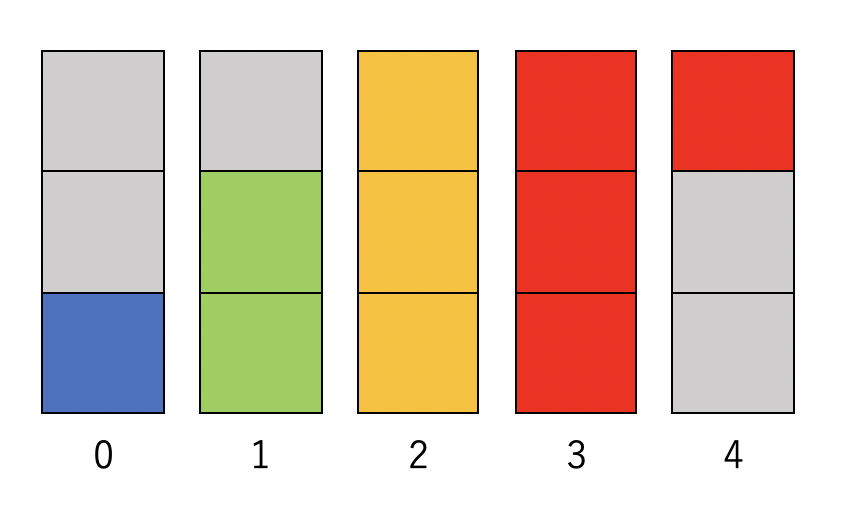
それぞれの箱が、一種類か二種類の色で塗られており、それぞれの色の面積の合計が元の重みに対応していることがわかるであろう。この箱ができたら、
- まず$N$個の箱から一様に一つ選ぶ
- 選ばれた箱に2つの色があったら、どちらを選ぶか確率的に決める
の2ステップでインデックスを選べる。どんなに$N$が大きくても2ステップでインデックスを選べるので、$O(1)$の方法となっていることがわかるであろう。この箱の作り方がやや難しいのだが、詳細は別記事を参照して欲しい。
箱を作るところから探索までを実装すると、例えばこんな感じになるだろう。
class walker_alias {
private:
unsigned int n;
unsigned int nb;
std::vector<int> index;
std::vector<double> prob;
std::vector<uint32_t> probi;
uint32_t int_max = ~static_cast<uint32_t>(0);
public:
const std::string name() {
return "Walker's Alias";
}
walker_alias(std::vector<double> &a) {
nb = 1;
while ((unsigned int)(1 << nb) <= a.size()) {
nb++;
}
n = (1 << nb);
index.resize(n, 0.0);
prob.resize(n, 0.0);
probi.resize(n, 0);
for (unsigned int i = 0; i < a.size(); i++) {
prob[i] = a[i];
}
double ave = std::accumulate(prob.begin(), prob.end(), 0.0) / prob.size();
for (auto &v : prob) {
v /= ave;
}
std::vector<int> small, large;
for (unsigned int i = 0; i < n; i++) {
if (prob[i] < 1.0) {
small.push_back(i);
} else {
large.push_back(i);
}
index[i] = i;
}
while (small.size() && large.size()) {
const int j = small.back();
small.pop_back();
const int k = large.back();
index[j] = k;
prob[k] = prob[k] - 1.0 + prob[j];
if (prob[k] < 1.0) {
small.push_back(k);
large.pop_back();
}
}
const int imax = int_max >> nb;
for (unsigned int i = 0; i < n; i++) {
probi[i] = static_cast<uint32_t>(prob[i] * imax);
}
}
int select(std::mt19937 &mt) {
uint32_t r = mt();
int k = r & (n - 1);
r = r >> nb;
if (r > probi[k]) {
return index[k];
} else {
return k;
}
}
};
詳しいアルゴリズムを知らないと、何をやっているか理解するのは難しいと思う。ここでは二回乱数を振るかわりに、一つの乱数の上位ビットと下位ビットを「箱の選択」「箱内の選択」に分けて使うことで、乱数生成回数を一度にしている。
この方法は箱の準備が$O(N)$、探索が$O(1)$だが、一部でも重みが変更されたら箱は全て作り直しなので、更新も$O(N)$である。
二分木探索
さて、累積和の方法も、Walker’s Alias法も、重みの部分更新に対応していなかった。そこで、二分木を作ることで部分更新に対応する。
二分木による重み付きサンプリングは、毎回、残りのグループを2つに分けて、そのどちらかを確率的に選ぶことで、最終的に欲しいインデックスに到達する、というアルゴリズムである。
木の作り方だが、まず一番下に配列の重みを並べる。もし$N$が2のベキでなければ、ちょうど2のベキになるように0埋めする。
一番下に重みが並んだら、隣り合うインデックスの重みを合計し、それを上の階層のノードの重みとする。これを繰り返すとトーナメント表のような二分木ができあがる。
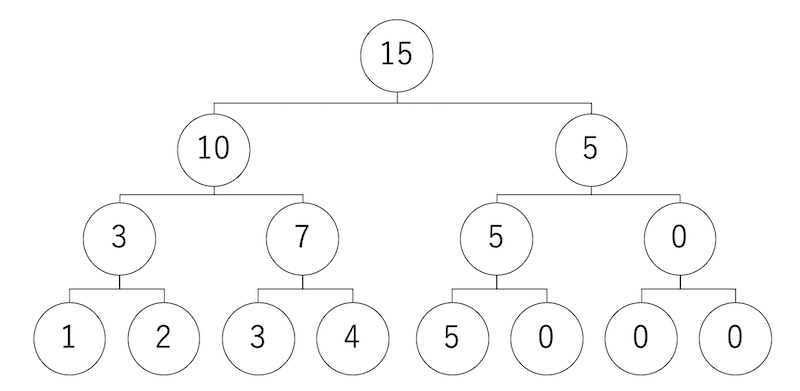
この二分木から、インデックスを探すには以下のようにする。
まず、一番上のルートノードからスタートする。この重みは15なので、0〜15の一様乱数を振る。得られた乱数が、自分の左の子供の数字より小さければ左下へ、そうでなければ右下へ移動する。
移動先でも同じことを繰り返す。例えば一番最初に0〜15の乱数を振って「8」が出たら、これは「10」より小さいので左下の「10」のノードに移動する。今度は0〜10の乱数を振って「5」が出たとすると、今度は左したの「3」より大きいので右下に移動する。このようにして一番下まで到達した時、そのノードのインデックスが欲しいインデックスである。
これが正しく重み付きサンプリングになっていることは直感的に明らかであろうが、念の為ちゃんと説明しておくと、まず、(0埋めしたノードも含めて)8個の要素を、4個ずつ2つのグループに分ける。左グループの重みは1,2,3,4で合計10。右グループの重みは5,0,0,0で、合計5である。この合計重みに従って、「最終的な勝者がどちらのグループに含まれるか」を選択する。たとえばここで左が選ばれたとすると、今度は1,2のグループと3,4のグループに分ける。重みは3対7であり、その重みでグループを選ぶ。このようにして選べば、最終的に重みに比例して最下層ノードが選ばれることは明らかであろう。
さて、この二分木探索のメリットは、部分更新に対応していることである。例えば、最下層の左から三番目のノードの重みが「3」から「6」に変更になったとしよう。この時、更新すべきは、このトーナメントで関係する場所だけである。この例だと、4つのノードだけ更新すれば良い。更新すべきノードは、サイズ$N$に対して$O(\log(N))$なのは明らかであろう。
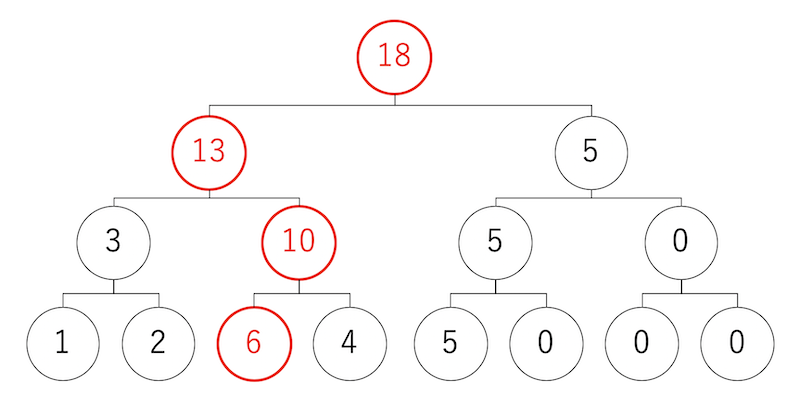
実行結果
というわけで、以上を実装して、テストしてみよう。先程のリポジトリ
https://github.com/kaityo256/randomsampling
をcloneしてmake、実行すると、入力配列として[1,2,3,4,5]を与え、3つのアルゴリズム、Walker’s alias、累積和(Cumulative Sum)、二分木探索(Binary Tree)それぞれについて、入力配列の重み通りにインデックスをサンプリングできているか確認後、二分木探索のみ重み3を6に変更し、変更後も正しくサンプリングできているかを確認する。結果はこんな感じになる。
$ make
$ ./a.out
Input Data
0:1
1:2
2:3
3:4
4:5
Walker's Alias
0:1.00905
1:1.9854
2:3.00285
3:3.96615
4:5.03655
Cumulative Sum
0:1.0233
1:2.0007
2:3.01125
3:3.98685
4:4.9779
Binary Tree
0:0.9807
1:1.99695
2:3.0114
3:4.00035
4:5.0106
Partial Update
2:3->6
Binary Tree
0:0.9693
1:1.98018
2:6.03882
3:3.9987
4:5.013
ちゃんと重みが1:2:3:4:5になっており、部分更新も正しくできていることがわかる。
まとめ
重み付きサンプリングアルゴリズムを3つ紹介した。それぞれのアルゴリズムの、テーブル構築、探索、部分更新の手間は以下の通りである。
| テーブル構築 | 探索 | 部分更新 | |
|---|---|---|---|
| 累積和 | O(N) | O(log N) | O(N) |
| Walker’s Alias | O(N) | O(1) | O(N) |
| 二分木 | O(N) | O(log N) | O(log N) |
通常は累積和かWalker’s Aliasを使えば良いと思うが、例えば「サンプリングするたびに、毎回選ばれたインデックスの重みが変わる」という場合には二分木探索の方が適している。そういうことはあまりないが、稀にあるので覚えておくと面白いかもしれない。
実際、僕は二分木探索が必要になったことがある。詳細は以下の論文を見て欲しいが、時間があったら記事を書くかもしれない1。
- H. Watanabe, S. Yukawa, M. A. Novotny and N. Ito, [Phys. Rev. E, 74, 026707 (2006)(https://journals.aps.org/pre/abstract/10.1103/PhysRevE.74.026707)].
-
部分更新を伴う二分木探索による重み付きサンプリングアルゴリズムは、一応僕のオリジナルのつもりなのだが、誰かが考えそうではあるので、もしかしたら先行研究があるかもしれない。 ↩